Semantic
General
See also Data, Documents, Open social#Semantic, HTML/CSS
a very messy page
- Semantic Web - a “Web of data,” the sort of data you find in databases. The ultimate goal of the Web of data is to enable computers to do more useful work and to develop systems that can support trusted interactions over the network. The term “Semantic Web” refers to W3C’s vision of the Web of linked data. Semantic Web technologies enable people to create data stores on the Web, build vocabularies, and write rules for handling data. Linked data are empowered by technologies such as RDF, SPARQL, OWL, and SKOS.
- http://en.wikipedia.org/wiki/Semantic_Web - ggg (giant global graph)
- -2003.02320- Knowledge Graphs - In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs. [3]
- Use URIs to denote things.
- Use HTTP URIs so that these things can be referred to and looked up ("dereferenced") by people and user agents.
- Provide useful information about the thing when its URI is dereferenced, leveraging standards such as RDF, SPARQL.
- Include links to other related things (using their URIs) when publishing data on the Web.
or
- All kinds of conceptual things, they have names now that start with HTTP.
- I get important information back. I will get back some data in a standard format which is kind of useful data that somebody might like to know about that thing, about that event.
- I get back that information it's not just got somebody's height and weight and when they were born, it's got relationships. And when it has relationships, whenever it expresses a relationship then the other thing that it's related to is given one of those names that starts with HTTP.
On the Semantic Web, vocabularies define the concepts and relationships (also referred to as “terms”) used to describe and represent an area of concern. Vocabularies are used to classify the terms that can be used in a particular application, characterize possible relationships, and define possible constraints on using those terms. In practice, vocabularies can be very complex (with several thousands of terms) or very simple (describing one or two concepts only).
There is no clear division between what is referred to as “vocabularies” and “ontologies”. The trend is to use the word “ontology” for more complex, and possibly quite formal collection of terms, whereas “vocabulary” is used when such strict formalism is not necessarily used or only in a very loose sense. Vocabularies are the basic building blocks for inference techniques on the Semantic Web.
- https://www.w3.org/wiki/LDP_Implementations - This is community-maintained page listing planned and existing implementations of the Linked Data Platform (LDP). If you are associated with such an implementation (planned or complete), please make sure it is correctly listed on this page. See the LDP compliance reports for those implementations who have supplied testing results.
- Agile Knowledge Engineering and Semantic Web (AKSW) is hosted by the Chair of Business Information Systems (BIS) of the Institute of Computer Science (IfI) / University of Leipzig as well as the Institute for Applied Informatics (InfAI). Goals: Development of methods, tools and applications for adaptive Knowledge Engineering in the context of the Semantic Web. Research of underlying Semantic Web technologies and development of fundamental Semantic Web tools and applications. Maturation of strategies for fruitfully combining the Social Web paradigms with semantic knowledge representation techniques.
- EUCLID | EdUcational Curriculum for the usage of LInked Data - a European project facilitating professional training for data practitioners, who aim to use Linked Data in their daily work. EUCLID delivers a curriculum implemented as a combination of living learning materials and activities (eBook series, webinars, face‐to‐face training), validated by the user community through continuous feedback
- Sindice - Data Web Services. Millions of websites mark up their content using RDF, Microformats, Microdata, Schema.org, RDFa, Opengraph and more. Sindice helps you find, understand and integrate with their content.
- http://nets.ii.uam.es/~neptuno/publications/neptuno-esws04.pdf
- http://www.public.asu.edu/~hdavulcu/VLDB-WS03.pdf
- http://eb.ie.nthu.edu.tw/File/Faculty/Journal/J-08-A%20fuzzy%20ontological%20knowledge%20document%20clustering%20methodology.pdf
- http://dl.acm.org/citation.cfm?id=500767
- http://www.inf.unibz.it/dis/research/seminar_slides/hayes.pdf
- http://eprints.qut.edu.au/30315/1/Cher_Lau_Thesis.pdf
- http://www.is.informatik.uni-kiel.de/~thalheim/vorlesungen/Wirtschaftsinformatik/KnowledgeGridEJC10.pdf
- http://www.ontopia.net/topicmaps/materials/identitycrisis.html
- http://www.ltg.ed.ac.uk/~ht/eSI_URIs.html
- http://www.w3.org/2000/10/swap/ - Semantic Web Application Platform
- http://www.w3.org/2000/10/swap/doc/cwm.html
News
- http://semanticweb.com - business news
Historic
MCF
- Meta Content Framework Using XML - Submitted to W3C 6 June 97, R.V. Guha (Netscape Communications), Tim Bray (Textuality)
- An MCF[/XML Tutorial] - a tool to provide information about information. The primary goal is to make the Web (Internet or Intranet) more like a library and less like a messy heap of books on the floor. In order to understand MCF, there are three things that you'll need to learn: Objects, Categories, and Properties - the conceptual building blocks, The XML syntax in which MCF is stored, The Directed Linked Graph mathematical model which lies behind MCF, which can be used by computer programmers to build efficient MCF implementations.
- https://en.wikipedia.org/wiki/Meta_Content_Framework - a specification of a content format for structuring metadata about web sites and other data. MCF was developed by Ramanathan V. Guha at Apple Computer's Advanced Technology Group between 1995 and 1997. Rooted in knowledge-representation systems such as CycL, KRL, and KIF, it sought to describe objects, their attributes, and the relationships between them. When the research project was discontinued, Guha left Apple for Netscape, where, in collaboration with Tim Bray, he adapted MCF to use XML and created the first version of the Resource Description Framework (RDF).
- Index of /mcf
- Meta Content Framework
- Towards a theory of meta-content - This document makes a case for a more principled approach to meta-content. In particular I argue for the use of an single expressive language for encoding meta-content irrespective of the source, location or format of the content itself.
SHOE
- https://en.wikipedia.org/wiki/Simple_HTML_Ontology_Extensions - a small set of HTML extensions designed to give web pages semantic meaning by allowing information such as class, subclass and property relationships. SHOE was developed around 1996 by Sean Luke, Lee Spector, James Hendler, Jeff Heflin, and David Rager at the University of Maryland, College Park.
DAML+OIL
- https://en.wikipedia.org/wiki/DARPA_Agent_Markup_Language - was the name of a US funding program at the US Defense Advanced Research Projects Agency (DARPA) started in 1999 by then-Program Manager James Hendler, and later run by Murray Burke, Mark Greaves and Michael Pagels. The program focused on the creation of machine-readable representations for the Web. One of the Investigators working on the program was Tim Berners-Lee and to a great degree through his influence, working with the program managers, the effort worked to create technologies and demonstrations for what is now called the Semantic Web and this in turn led to the growth of Knowledge Graph technology.A primary outcome of the DAML program was the DAML language, an agent markup language based on RDF. This language was then followed by an extension entitled DAML+OIL which included researchers outside of the DARPA program in the design. The 2002 submission of the DAML+OIL language to the World Wide Web Consortium (W3C) captures the work done by DAML contractors and the EU/U.S. ad hoc Joint Committee on Markup Languages. This submission was the starting point for the language (later called OWL) to be developed by W3C's web ontology working group, WebOnt.
DAML+OIL was a syntax, layered on RDF and XML, that could be used to describe sets of facts making up an ontology.DAML+OIL had its roots in three main languages - DAML, as described above, OIL (Ontology Inference Layer) and SHOE, an earlier US research project.A major innovation of the languages was to use RDF and XML for a basis, and to use RDF namespaces to organize and assist with the integration of arbitrarily many different and incompatible ontologies. Articulation ontologies can link these competing ontologies through codification of analogous subsets in a neutral point of view, as is done in the Wikipedia.Current ontology research derived in part from DAML is leading toward the expression of ontologies and rules for reasoning and action.Much of the work in DAML has now been incorporated into RDF Schema, the OWL and their successor languages and technologies including schema.org
- https://en.wikipedia.org/wiki/Ontology_Inference_Layer - can be regarded as an ontology infrastructure for the Semantic Web.[1] OIL is based on concepts developed in Description Logic (DL) and frame-based systems and is compatible with RDFS.OIL was developed by Dieter Fensel, Frank van Harmelen (Vrije Universiteit, Amsterdam) and Ian Horrocks (University of Manchester) as part of the IST OntoKnowledge project.Much of the work in OIL was subsequently incorporated into DAML+OIL and the Web Ontology Language (OWL).
RDF
- https://en.wikipedia.org/wiki/Resource_Description_Framework - a family of World Wide Web Consortium (W3C) specifications originally designed as a metadata data model. It has come to be used as a general method for conceptual description or modeling of information that is implemented in web resources, using a variety of syntax notations and data serialization formats. It is also used in knowledge management applications. RDF was adopted as a W3C recommendation in 1999. The RDF 1.0 specification was published in 2004, the RDF 1.1 specification in 2014.
The RDF data model is similar to classical conceptual modeling approaches (such as entity–relationship or class diagrams). It is based on the idea of making statements about resources (in particular web resources) in expressions of the form subject–predicate–object, known as triples. The subject denotes the resource, and the predicate denotes traits or aspects of the resource, and expresses a relationship between the subject and the object.For example, one way to represent the notion "The sky has the color blue" in RDF is as the triple: a subject denoting "the sky", a predicate denoting "has the color", and an object denoting "blue". Therefore, RDF uses subject instead of object (or entity) in contrast to the typical approach of an entity–attribute–value model in object-oriented design: entity (sky), attribute (color), and value (blue).
RDF is an abstract model with several serialization formats (i.e. file formats), so the particular encoding for resources or triples varies from format to format.This mechanism for describing resources is a major component in the W3C's Semantic Web activity: an evolutionary stage of the World Wide Web in which automated software can store, exchange, and use machine-readable information distributed throughout the Web, in turn enabling users to deal with the information with greater efficiency and certainty. RDF's simple data model and ability to model disparate, abstract concepts has also led to its increasing use in knowledge management applications unrelated to Semantic Web activity. A collection of RDF statements intrinsically represents a labeled, directed multi-graph. This in theory makes an RDF data model better suited to certain kinds of knowledge representation than are other relational or ontological models. However, in practice, RDF data is often stored in relational database or native representations (also called Triplestores—or Quad stores, if context such as the named graph is also stored for each RDF triple). As RDFS and OWL demonstrate, one can build additional ontology languages upon RDF.
- W3C: RDF Primer
- RDF data are sets of ‘triples’ (aka ‘statements’) of the form (Subject, Property, Object)
- RDF data are seen as (unranked, node- and edge-labeled) directed graphs
- nodes of which are statement's subjects and objects and are either labeled
- by URIs an thus representing Web resources
- by literals, such as strings or numbers, thus representing literal resources
- by ‘local’ identifiers thus representing ‘anonymous’ or ‘blank’ nodes.
- arcs of which correspond to statement's properties
- nodes of which are statement's subjects and objects and are either labeled
- Properties are also called ‘predicates’ (statement analogy)
- Blank nodes commonly used to aggregate or group statements
- e.g., in containers or collections
- or for n-ary relations
RDF is a general method to decompose any type of knowledge into small pieces, with some rules about the semantics, or meaning, of those pieces. The point is to have a method so simple that it can express any fact, and yet so structured that computer applications can do useful things with it.
The basic unit of RDF is a statement called a triple. One can think of a triple as a type of sentence that states a single "fact" about a resource. RDF allows you to define statements about things (or resources), in the form of subject-predicate-object expressions (known as RDF-triples due to the 3 constituent parts).
- Different RDF Formats - March 11 2013
The different forms for representing the RDF data are:
- RDF/XML
- Notation-3 (N3)
- Turtle - a simplified, RDF-only subset of N3.
- N-Triple
- RDFa
- TRiX
- TRiG
- JSON-LD
RDF/XML
Here's some RDF XML:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ns="http://www.example.org/#">
<ns:Person rdf:about="http://www.example.org/#john"> <ns:hasMother rdf:resource="http://www.example.org/#susan" /> <ns:hasFather> <rdf:Description rdf:about="http://www.example.org/#richard"> <ns:hasBrother rdf:resource="http://www.example.org/#luke" /> </rdf:Description> </ns:hasFather> </ns:Person> </rdf:RDF>
N3
Here's some N3 RDF:
@prefix : <http://www.example.org/> . :john a :Person . :john :hasMother :susan . :john :hasFather :richard . :richard :hasBrother :luke .
N-Triple
Turtle
TriG
- TriG - RDF Dataset Language. A concrete syntax for RDF as defined in the RDF Concepts and Abstract Syntax ([rdf11-concepts]). TriG is an extension of Turtle ([turtle]), extended to support representing a complete RDF Dataset.
RDFa
2004. RDFa 1.1 reached recommendation status in June 2012.
- RDFa - an extension to HTML5 that helps you markup things like People, Places, Events, Recipes and Reviews. Search Engines and Web Services use this markup to generate better search listings and give you better visibility on the Web, so that people can find your website more easily.
- HTML+RDFa 1.1 - Support for RDFa in HTML4 and HTML5 [5]
- https://github.com/rdfa/librdfa - SAX-based implementation of an RDFa Processor in C
JSON-LD
- JSON-LD 1.1 - a useful data serialization and messaging format. This specification defines JSON-LD, a JSON-based format to serialize Linked Data. The syntax is designed to easily integrate into deployed systems that already use JSON, and provides a smooth upgrade path from JSON to JSON-LD. It is primarily intended to be a way to use Linked Data in Web-based programming environments, to build interoperable Web services, and to store Linked Data in JSON-based storage engines.
- http://en.wikipedia.org/wiki/JSON-LD - RDF serialised as JSON not XML
- http://manu.sporny.org/2013/json-ld-is-the-bees-knees - "JSON-LD was created by people that have been directly involved in the Linked Data, lowercase semantic web, uppercase Semantic Web, Microformats, Microdata, and RDFa work. It has proven to be useful to them. There are a number of very large technology companies that have adopted JSON-LD, further underscoring its utility."
"Full Disclosure: I am one of the primary creators of JSON-LD, lead editor on the JSON-LD 1.0 specification, and chair of the JSON-LD Community Group. These are my personal opinions and not the opinions of the W3C, JSON-LD Community Group, or my company. ... TL;DR: The desire for better Web APIs is what motivated the creation of JSON-LD, not the Semantic Web. If you want to make the Semantic Web a reality, stop making the case for it and spend your time doing something more useful, like actually making machines smarter or helping people publish data in a way that’s useful to them."
to sort
- RDF HDT (Header, Dictionary, Triples) is a compact data structure and binary serialization format for RDF that keeps big datasets compressed to save space while maintaining search and browse operations without prior decompression. This makes it an ideal format for storing and sharing RDF datasets on the Web.
- http://www.w3.org/TR/microdata-rdf
- http://www.thedigitalshift.com/2012/02/roy-tennant-digital-libraries/why-microdata-not-rdf-will-power-the-semantic-web/
- http://manu.sporny.org/2013/microdata-downward-spiral/
- Atomate It! End-user Context-Sensitive Automation using Heterogeneous Information Sources on the Web
Ontologies
There is no clear division between what is referred to as “vocabularies” and “ontologies”. The trend is to use the word “ontology” for more complex, and possibly quite formal collection of terms, whereas “vocabulary” is used when such strict formalism is not necessarily used or only in a very loose sense. Vocabularies are the basic building blocks for inference techniques on the Semantic Web.
- http://semanticweb.org/wiki/Ontology
- https://en.wikipedia.org/wiki/Ontology_(information_science)#Examples_of_published_ontologies
- http://www.service-finder.eu/ontologies/ServiceOntology
- vocab.org is intended to be an open URI space for vocabularies such as RDF Schemas or XML Namespace documents. The PURL http://purl.org/vocab/ is mapped to this domain. It is recommended that all vocabularies hosted here define their term URIs using the PURL rather than the vocab.org domain. The PURL is expected to persist longer than vocab.org, although every effort will be made to ensure that vocab.org persists for as long as possible.
- UMBEL - Vocabulary and Reference Concept Ontology (namespace: umbel). UMBEL is the Upper Mapping and Binding Exchange Layer, designed to help content interoperate on the Web.
XSD
- XSD Datatypes - RDF Working Group Wiki - This table lists the XSD datatypes present in the datatype maps defined for RDF, OWL, SPARQL, and RIF.
- XML Schema Datatypes in RDF and OWL - The RDF and OWL Recommendations use the simple types from XML Schema. This document addresses three questions left unanswered by these Recommendations: Which URIref should be used to refer to a user defined datatype? Which values of which XML Schema simple types are the same? How to use the problematic xsd:duration in RDF and OWL? In addition, we further describe how to integrate OWL DL with user defined datatypes (in appendix B).
Dublin Core
- DCMI: Dublin Core™ - The original Dublin Core™ of thirteen (later fifteen) elements was first published in the report of a workshop in 1995. In 1998, this was formalized in the Internet Engineering Task Force standard RFC 5791, and discussions began about making it a standard of the (US) National Information Standards Organization (NISO). This led to the publication of ANSI/NISO Z39.85-2001 and the International Standards Organization Standard 15836-2003. The most recent updates of these standards are RFC 5791 (2010), Z39-85-2012, and ISO 15836-1:2017. Publication of a Part 2 to the ISO standard, covering several dozen properties and classes that have been added to DCMI namespaces since 1999, is expected in 2019.Starting in 2002, DCMI grew into the role of "de facto" standards agency by maintaining its own, updated documentation for DCMI Metadata Terms. The DCMI Usage Board currently serves as the maintenance agency for ISO 15836.In addition to these semantic specifications, DCMI working groups have developed specifications on other topics of relevance to metadata, such as encoding syntaxes, usage guidelines, and metadata models. In the rapidly evolving environment of the World Wide Web, most of these specifications have been superseded over time, sometimes after influencing subsequent work by other technical communities, notably the World Wide Web Consortium.
- DCMI: DCMI Metadata Terms - This document is an up-to-date specification of all metadata terms maintained by the Dublin Core Metadata Initiative, including properties, vocabulary encoding schemes, syntax encoding schemes, and classes.
FOAF
- The FOAF Project - a computer language defining a dictionary of people-related terms that can be used in structured data (e.g. RDFa, JSON-LD, Linked Data).
- FOAF Vocabulary Specification - a project devoted to linking people and information using the Web. Regardless of whether information is in people's heads, in physical or digital documents, or in the form of factual data, it can be linked. FOAF integrates three kinds of network: social networks of human collaboration, friendship and association; representational networks that describe a simplified view of a cartoon universe in factual terms, and information networks that use Web-based linking to share independently published descriptions of this inter-connected world. FOAF does not compete with socially-oriented Web sites; rather it provides an approach in which different sites can tell different parts of the larger story, and by which users can retain some control over their information in a non-proprietary format.
Web of Trust
- WOT Schema - RDF documents can make any number of statements. Without some kind of signature or other similar verification mechanism, there is no way to understand who made these statements. One way to document who made a set of statements is via the use of Digital Signatures: signing a document using Public Key Cryptography. The WOT, or Web Of Trust, schema is designed to facilitate the use of Public Key Cryptography tools such as PGP or GPG to sign RDF documents and document these signatures.
MetaVocab
Creative Commons
SKOS
- SKOS: Simple Knowledge Organization System - an area of work developing specifications and standards to support the use of knowledge organization systems (KOS) such as thesauri, classification schemes, subject heading systems and taxonomies within the framework of the Semantic Web.SKOS & RDFSKOS provides a standard way to represent knowledge organization systems using the Resource Description Framework (RDF). Encoding this information in RDF allows it to be passed between computer applications in an interoperable way.Using RDF also allows knowledge organization systems to be used in distributed, decentralised metadata applications. Decentralised metadata is becoming a typical scenario, where service providers want to add value to metadata harvested from multiple sources.
DOAP
- DOAP is a project to create an XML/RDF vocabulary to describe software projects, and in particular open source projects.
SIOC
- http://rdfs.org/ - SIOC, ResumeRDF, SCOT
- SIOC initiative (Semantically-Interlinked Online Communities) aims to enable the integration of online community information. SIOC provides a Semantic Web ontology for representing rich data from the Social Web in RDF. It has recently achieved significant adoption through its usage in a variety of commercial and open-source software applications, and is commonly used in conjunction with the FOAF vocabulary for expressing personal profile and social networking information. By becoming a standard way for expressing user-generated content from such sites, SIOC enables new kinds of usage scenarios for online community site data, and allows innovative semantic applications to be built on top of the existing Social Web. The SIOC ontology was recently published as a W3C Member Submission, which was submitted by 16 organisations.
ResumeRDF
SCOT
- SCOT is an acronym for Social Semantic Cloud of Tags. The name was chosen to emphasise the goal of providing a consistent framework for expressing social tagging at a semantic level in machine-understandable way. The SCOT ontology provides a model for expressing the main concepts and properties required to describe information for tagging activities (e.g., users, tags, resources, etc.) on the Semantic Web. This document contains a detailed description of the SCOT Ontology.
Data Cube
- RDF Data Cube Vocabulary - There are many situations where it would be useful to be able to publish multi-dimensional data, such as statistics, on the web in such a way that it can be linked to related data sets and concepts. The Data Cube vocabulary provides a means to do this using the W3C RDF (Resource Description Framework) standard. The model underpinning the Data Cube vocabulary is compatible with the cube model that underlies SDMX (Statistical Data and Metadata eXchange), an ISO standard for exchanging and sharing statistical data and metadata among organizations. The Data Cube vocabulary is a core foundation which supports extension vocabularies to enable publication of other aspects of statistical data flows or other multi-dimensional data sets.
Other
- Vocabulary of Interlinked Datasets (VoID) is an RDF Schema vocabulary for expressing metadata about RDF datasets. It is intended as a bridge between the publishers and users of RDF data, with applications ranging from data discovery to cataloging and archiving of datasets. This document provides a formal definition of the new RDF classes and properties introduced for VoID. It is a companion to the main specification document for VoID, Describing Linked Datasets with the VoID Vocabulary.
- Schema.RDFS.org - In early June 2011, the three big search engines Bing, Google and Yahoo! introduced Schema.org, a collection of terms that webmasters can use to markup their pages to improve the display of search results. This site is a complementary effort by people from the Linked Data community to support Schema.org deployment and usage with a special focus on Linked Data:
- Common Tag is an open tagging format developed to make content more connected, discoverable and engaging. Unlike free-text tags, Common Tags are references to unique, well-defined concepts, complete with metadata and their own URLs. With Common Tag, site owners can more easily create topic hubs, cross-promote their content, and enrich their pages with free data, images and widgets.
- Music Ontology is an attempt to provide a vocabulary for linking a wide range music-related information, and to provide a democratic mechanism for doing so
- BIO: A vocabulary for biographical information. used in FOAF
- oeGOV is making and publishing W3C OWL ontologies for eGovernment.
- http://iswc2011.semanticweb.org/fileadmin/iswc/Papers/PostersDemos/swc/swc2011_submission_1.pdf
- http://dl.acm.org/citation.cfm?id=2396761.2398467
- http://vocab.org/relationship/.html
- http://motools.sourceforge.net/event/event.html#
- http://smiy.sourceforge.net/ao/spec/associationontology.html#
- http://smiy.sourceforge.net/rec/spec/recommendationontology.html#
- http://vocab.deri.ie/ppo
- http://ontorule-project.eu/ ONTORULE (ONTOlogies meet business RULEs) is a large-scale integrating project (IP) partially funded by the European Union's 7th Framework Programme under the Information and Communication Technologies
- Product Types Ontology - High-precision identifiers for product types based on Wikipedia. Provides ca. 300,000 precise definitions for types of product or services that extend the schema.org and GoodRelations standards for e-commerce markup.
VOAF
- VOAF is a vocabulary specification providing elements allowing the description of vocabularies (RDFS vocabularies or OWL ontologies) used in the Linked Data Cloud. In particular it provides properties expressing the different ways such vocabularies can rely on, extend, specify, annotate or otherwise link to each other. It relies itself on Dublin Core and voiD. The name of the vocabulary makes an explicit reference to FOAF because VOAF can be used to define networks of vocabularies in a way similar to the one FOAF is used to define networks of people.
LOV
LOV objective is to provide easy access methods to this ecosystem of vocabularies, and in particular by making explicit the ways they link to each other and providing metrics on how they are used in the linked data cloud, help to improve their understanding, visibility and usability, and overall quality.
Ontology languages
RDF Schema / RDFS
- https://en.wikipedia.org/wiki/RDF_Schema - Resource Description Framework Schema, variously abbreviated as RDFS, RDF(S), RDF-S, or RDF/S) is a set of classes with certain properties using the RDF extensible knowledge representation data model, providing basic elements for the description of ontologies, otherwise called RDF vocabularies, intended to structure RDF resources. These resources can be saved in a triplestore to reach them with the query language SPARQL.The first versio was published by the World-Wide Web Consortium (W3C) in April 1998, and the final W3C recommendation was released in February 2004. Many RDFS components are included in the more expressive Web Ontology Language (OWL).
- W3C: RDF Vocabulary Description Language 1.0: RDF Schema (RDFS)
- W3C: http://www.w3.org/TR/rdf-mt/ RDF Semantics - a specification of a precise semantics, and corresponding complete systems of inference rules, for the Resource Description Framework (RDF) and RDF Schema (RDFS).
- RDF/S allows so-called RDF Schemas (or ontologies) similar to object-oriented class hierarchies or taxonomies
- Inheritance model of RDF/S exhibits the following peculiarities:
- same resource may be classified in different, unrelated classes
- class hierarchy may be cyclic → all classes on cycle equivalent
- properties are first-class
- associates range and domain to property, rather than which properties a class can carry
- Inference rules are used to define the semantics (or entailment) of an RDF/S schema
- e.g., transitivity of the class hierarchy or
- inferred type of an untyped resource in the domain of a property
OWL
- OWL - a Web Ontology language. Where earlier languages have been used to develop tools and ontologies for specific user communities (particularly in the sciences and in company-specific e-commerce applications), they were not defined to be compatible with the architecture of the World Wide Web in general, and the Semantic Web in particular. OWL uses both URIs for naming and the description framework for the Web provided by RDF to add the following capabilities to ontologies: Ability to be distributed across many systems, Scalability to Web needs, Compatibility with Web standards for accessibility and internationalization, Openess and extensiblility. OWL builds on RDF and RDF Schema and adds more vocabulary for describing properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
- http://www.w3.org/TR/owl-features
- http://www.w3.org/TR/owl-guide
- http://www.w3.org/TR/owl-semantics
- http://www.w3.org/TR/owl-ref
newer;
- OWL 2 Web Ontology Language Quick Reference Guide
- OWL 2 Web Ontology Language Document Overview
- OWL 2 Web Ontology Language Primer
- OWL 2 Web Ontology Language Structural Specification and Functional-Style Syntax
- OWL 2 Web Ontology Language Manchester Syntax
- OWL 2 Web Ontology Language RDF-Based Semantics
- OWL 2 Web Ontology Language Profiles
- New Messages! - RDFS allows you to express the relationships between things by standardizing on a flexible, triple-based format and then providing a vocabulary (“keywords” such as rdf:type or rdfs:subClassOf) which can be used to say things. OWL is similar, but bigger, better, and badder. OWL lets you say much more about your data model, it shows you how to work efficiently with database queries and automatic reasoners, and it provides useful annotations for bringing your data models into the real world.
- OWL 2 Web Ontology Language Mapping to RDF Graphs (Second Edition) - The OWL 2 Web Ontology Language, informally OWL 2, is an ontology language for the Semantic Web with formally defined meaning. OWL 2 ontologies provide classes, properties, individuals, and data values and are stored as Semantic Web documents. OWL 2 ontologies can be used along with information written in RDF, and OWL 2 ontologies themselves are primarily exchanged as RDF documents. The OWL 2 Document Overview describes the overall state of OWL 2, and should be read before other OWL 2 documents.This document defines the mapping of OWL 2 ontologies into RDF graphs, and vice versa.
- https://en.wikipedia.org/wiki/Synonym_ring - or synset, is a group of data elements that are considered semantically equivalent for the purposes of information retrieval. These data elements are frequently found in different metadata registries. Although a group of terms can be considered equivalent, metadata registries store the synonyms at a central location called the preferred data element. According to WordNet, a synset or synonym set is defined as a set of one or more synonyms that are interchangeable in some context without changing the truth value of the proposition in which they are embedded. A synonym ring can be expressed by a series of statements in the Web Ontology Language (OWL) using the classEquivalence or the propertyEquivalence or instance equivalence statement – the sameAs property.
- PR-OWL - an open research work aimed to extend the OWL ontology Web language so it can represent probabilistic ontologies. In other words, it is a probabilistic extension to OWL that provides a framework for authoring probabilistic ontologies and is based on the Bayesian first-order logic called Multi-Entity Bayesian Networks (MEBN).
- https://en.wikipedia.org/wiki/Multimedia_Web_Ontology_Language - an ontology representation language that enables such perceptual modeling. It assumes a causal model of the world, where observable media features are caused by underlying concepts. In MOWL, it is possible to associate different types of media features in different media format and at different levels of abstraction with the concepts in a closed domain. The associations are probabilistic in nature to account for inherent uncertainties in observation of media patterns. The spatial and temporal relations between the media properties characterizing a concept (or, event) can also be expressed using MOWL. Often the concepts in a domain inherit the media properties of some related concepts, such as a historic monument inheriting the color and texture properties of its building material. It is possible to reason with the media properties of the concepts in a domain to derive an Observation Model for a concept. Finally, MOWL supports an abductive reasoning framework using Bayesian networks, that is robust against imperfect observations of media data.
- Visual Data Web - Visually Experiencing the Data Web - provides an overview of our attempts to a more visual Data Web.The term Data Web refers to the evolution of a mainly document-centric Web toward a more data-oriented Web. In its narrow sense, the term describes pragmatic approaches of the Semantic Web, such as RDF and Linked Data. In a broader sense, it also includes less formal data structures, such as microformats, microdata, tagging, and folksonomies.The term Visual Data Web reflects our goal of making the Data Web visually more experienceable, also for average Web users with little to no knowledge about the underlying technologies. This website presents developments, related publications, and current activities to generate new ideas, methods, and tools that help making the Data Web easier accessible, more visible, and thus more attractive.
- https://github.com/VisualDataWeb/OWL2VOWL - Converting ontologies for WebVOWL
- WebVOWL - Web-based Visualization of Ontologies
RIF
SWRL
- https://en.wikipedia.org/wiki/Semantic_Web_Rule_Language - a proposed language for the Semantic Web that can be used to express rules as well as logic, combining OWL DL or OWL Lite with a subset of the Rule Markup Language (itself a subset of Datalog). The specification was submitted in May 2004 to the W3C by the National Research Council of Canada, Network Inference (since acquired by webMethods), and Stanford University in association with the Joint US/EU ad hoc Agent Markup Language Committee. The specification was based on an earlier proposal for an OWL rules language. SWRL has the full power of OWL DL, but at the price of decidability and practical implementations. However, decidability can be regained by restricting the form of admissible rules, typically by imposing a suitable safety condition.
Query languages
- http://www.en.pms.ifi.lmu.de/publications/PMS-FB/PMS-FB-2005-14.pdf
- http://www.en.pms.ifi.lmu.de/publications/PMS-FB/PMS-FB-2006-33/slides/rw2006.slides.html
SPARQL
- http://sparqles.okfn.org/ - endpoint status
RDQL
GRDDL
- GRDDL is a mechanism for Gleaning Resource Descriptions from Dialects of Languages. It is a technique for obtaining RDF data from XML documents and in particular XHTML pages. Authors may explicitly associate documents with transformation algorithms, typically represented in XSLT, using a link element in the head of the document. Alternatively, the information needed to obtain the transformation may be held in an associated metadata profile document or namespace document.
- http://www.slideshare.net/chimezie/grddl-the-why-what-how-and-where
- http://microformats.org/wiki/grddl
- http://www.w3.org/2003/g/data-view
Description Logic
- Description Logic workshops are the main international event of the description logic research community. They take place annually and aim at being an informal get-together that allows researchers to discuss the current developments in the area. The workshops explicitly welcome submissions from researchers that are new to the area and provide quality feedback via peer-reviewing while at the same time being of an "inclusive" nature with a very high acceptance rate. There are only informal (electronic) proceedings and "publication" at the workshop is not supposed to preclude publication at conferences.
- Description Logics as Ontology Languages for the Semantic Web [7]
- A Fuzzy Description Logic for the Semantic Web
Linked Open Data
- W3C: Linking Open Data - The Open Data Movement aims at making data freely available to everyone. There are already various interesting open data sets available on the Web. Examples include Wikipedia, Wikibooks, Geonames, MusicBrainz, WordNet, the DBLP bibliography and many more which are published under Creative Commons or Talis licenses. The goal of the W3C SWEO Linking Open Data community project is to extend the Web with a data commons by publishing various open data sets as RDF on the Web and by setting RDF links between data items from different data sources. RDF links enable you to navigate from a data item within one data source to related data items within other sources using a Semantic Web browser. RDF links can also be followed by the crawlers of Semantic Web search engines, which may provide sophisticated search and query capabilities over crawled data. As query results are structured data and not just links to HTML pages, they can be used within other applications.
- Linked Data is about using the Web to connect related data that wasn't previously linked, or using the Web to lower the barriers to linking data currently linked using other methods. More specifically, Wikipedia defines Linked Data as "a term used to describe a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF." This site exists to provide a home for, or pointers to, resources from across the Linked Data community.
{kind=link}
- datavisualization.ch: Introduction to Linked Open Data for Visualization Creators
- How to Publish Linked Data on the Web
- http://www.slideshare.net/DLFCLIR/intro-to-lod
- Learning Linked Data
- Learn Linked Data - Helping you get to grips with RDF, SPARQL & linked data.
- http://linkeddatabook.com/
- LOD cloud diagram shows datasets that have been published in Linked Data format, by contributors to the Linking Open Data community project and other individuals and organisations. It is based on metadata collected and curated by contributors to the Data Hub. Clicking the image will take you to an image map, where each dataset is a hyperlink to its homepage.
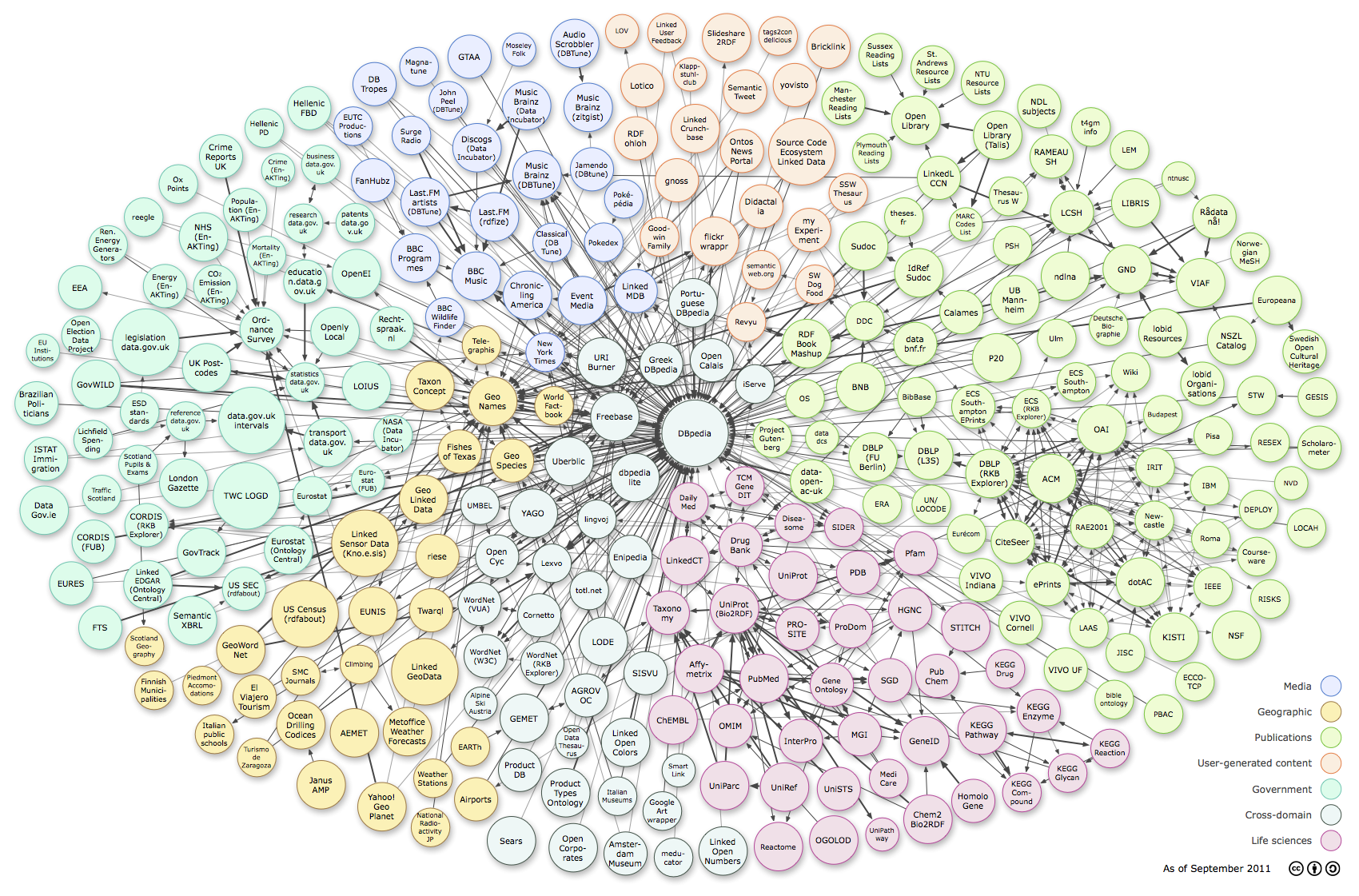{kind=link}
- LodLive project provides a demonstration of the use of Linked Data standards (RDF, SPARQL) to browse RDF resources. The application aims to spread linked data principles using a simple and friendly interface with reusable techniques.
- lobid.org - provides Linked Open Data (LOD) services for libraries, consisting of user interfaces (UIs) and application programming interfaces (APIs). lobid is run by the North Rhine-Westphalian Library Service Centre (hbz).
Future
Web Observatory
P2P
- Semantic Web Services and DHT-based Peer-to-Peer Networks: A New Symbiotic Relationship
- http://www.academia.edu/2820993/A_DHT-based_semantic_overlay_network_for_service_discovery
API
See WebDev#API
REST
- http://www.w3.org/TR/ldp/
- http://www.w3.org/2012/ldp/
- http://www.w3.org/2012/ldp/charter.html - Linked Data Platform (LDP) Working Group is to produce a W3C Recommendation for HTTP-based (RESTful) application integration patterns using read/write Linked Data. This work will benefit both small-scale in-browser applications (WebApps) and large-scale Enterprise Application Integration (EAI) efforts. It will complement SPARQL and will be compatible with standards for publishing Linked Data, bringing the data integration features of RDF to RESTful, data-oriented software development.
- http://lists.w3.org/Archives/Public/public-ldp-wg
- http://www.w3.org/Submission/ldbp/
Hydra
- Hydra is an effort to simplify the development of interoperable, hypermedia-driven Web APIs. The two fundamental building blocks of Hydra are JSON‑LD and the Hydra Core Vocabulary.
JSON‑LD is the serialization format used in the communication between the server and its clients. The Hydra Core Vocabulary represents the shared vocabulary between them. By specifying a number of concepts which are commonly used in Web APIs it can be used as the foundation to build Web services that share REST's benefits in terms of loose coupling, maintainability, evolvability, and scalability. Furthermore it enables the creation of generic API clients instead of requiring specialized clients for every single API.
Semantic forms
- https://github.com/jmvanel/semantic_forms - Form generators leveraging semantic web standards (RDF(S), OWL, SPARQL , ...
Validation
Search
Clustering
- http://papers.ssrn.com/sol3/papers.cfm?abstract_id=893985 - A Clustering Based Approach for Facilitating Semantic Web Service Discovery
- http://semwebmine2001.aifb.uni-karlsruhe.de/online/semwebmine03.pdf - Ontology Discovery for the Semantic Web Using Hierarchical Clustering
- http://www.valentinzacharias.de/papers/clustering.pdf - Clustering Ontology-based Metadata in the Semantic Web
- http://cs229.stanford.edu/proj2007/YangHuangHuang-SemanticWebsiteClustering.pdf - Semantic Website Clustering
- ftp://ftp.inf.puc-rio.br/pub/docs/techreports/06_23_cunha.pdf - Clustering The Semantic Web Challenge’s Applications: Architecture and Metadata Overview
Access control
See also Open social#WebID
Exploring
Protégé
- protégé - a free, open-source platform that provides a growing user community with a suite of tools to construct domain models and knowledge-based applications with ontologies.
- VOWL Plugin for Protégé - a Protégé plugin for the user-oriented visualization of ontologies. It implements the Visual Notation for OWL Ontologies (VOWL) by providing graphical depictions for elements of the Web Ontology Language (OWL) that are combined to a force-directed graph layout representing the ontology. ProtégéVOWL is based on VOWL 2, which focuses on the visualization of the ontology schema (i.e., the classes, properties and datatypes, also known as TBox).
RDF Gravity
- RDF Gravity - a tool for visualising RDF/OWL Graphs/ ontologies. Its main features are: Graph Visualization, Global and Local Filters (enabling specific views on a graph), Full text Search, Generating views from RDQL Queries, Visualising multiple RDF files, RDF Gravity is implemented by using the JUNG Graph API and Jena semantic web toolkit.
visualRDF
- visualRDF - aims to provide a nice graphical visualization of an RDF graph. a one night-fork from visualSPARQL, it will probably stay in this status for a while. visualRDF uses d3.js for rendering and ARC2 for parsing RDF.
SWOOP
to sort
Annotea
- Annotea - a W3C LEAD (Live Early Adoption and Demonstration) project under Semantic Web Advanced Development (SWAD). Annotea enhances collaboration via shared metadata based Web annotations, bookmarks, and their combinations. By annotations we mean comments, notes, explanations, or other types of external remarks that can be attached to any Web document or a selected part of the document without actually needing to touch the document. When the user gets the document he or she can also load the annotations attached to it from a selected annotation server or several servers and see what his peer group thinks. Similarly shared bookmarks can be attached to Web documents to help organize them under different topics, to easily find them later, to help find related material and to collaboratively filter bookmarked material.Annotea is open; it uses and helps to advance W3C standards when possible. For instance, we use an RDF based annotation schema for describing annotations as metadata and XPointer for locating the annotations in the annotated document. Similarly a bookmark schema describes the bookmark and topic metadata.Annotea is part of the Semantic Web efforts. It provides a RDF metadata based extendible framework for rich communication about Web pages while offering a simple annotation and bookmark user interface. The annotation metadata can be stored locally or in one or more annotation servers and presented to the user by a client capable of understanding this metadata and capable of interacting with an annotation server with the HTTP service protocol.
Amaya
- Amaya Home Page - a Web editor, i.e. a tool used to create and update documents directly on the Web. Browsing features are seamlessly integrated with the editing and remote access features in a uniform environment. This follows the original vision of the Web as a space for collaboration and not just a one-way publishing medium.Work on Amaya started at W3C in 1996 to showcase Web technologies in a fully-featured Web client. The main motivation for developing Amaya was to provide a framework that can integrate as many W3C technologies as possible. It is used to demonstrate these technologies in action while taking advantage of their combination in a single, consistent environment.Amaya started as an HTML + CSS style sheets editor. Since that time it was extended to support XML and an increasing number of XML applications such as the XHTML family, MathML, and SVG. It allows all those vocabularies to be edited simultaneously in compound documents.
Libs
- https://github.com/bbcrd/rdfsim - Python library helps generating a vector space from very large hierarchies encoded in RDF. An obvious example application is to generate a vector space from a SKOS hierarchy or an RDFS subclass hierarchy.
- Raptor RDF Syntax Library - a free software / Open Source C library that provides a set of parsers and serializers that generate Resource Description Framework (RDF) triples by parsing syntaxes or serialize the triples into a syntax. The supported parsing syntaxes are RDF/XML, N-Quads, N-Triples 1.0 and 1.1, TRiG, Turtle 2008 and 2013, RDFa 1.0 and 1.1, RSS tag soup including all versions of RSS, Atom 1.0 and 0.3, GRDDL and microformats for HTML, XHTML and XML. The serializing syntaxes are RDF/XML (regular, abbreviated, XMP), Turtle 2013, N-Quads, N-Triples 1.1, Atom 1.0, RSS 1.0, GraphViz DOT, HTML, JSON and mKR.
- https://github.com/lmatteis/mustache-rdf - Templating for RDF
- Rhizomik - The ReDeFer project is a compendium of RDF-aware utilities organised in a set of packages: RDF2HTML+RDFa: render a piece of RDF/XML as HTML+RDFa. XSD2OWL: transform an XML Schema into an OWL Ontology. CS2OWL: transform a MPEG-7 Classification Scheme into an OWL Ontology. XML2RDF: transform a piece of XML into RDF. RDF2SVG: render a piece of RDF/XML as a SVG showing the corresponding graph.
PHP
- ARC2 - a PHP 5.3 library for working with RDF. It also provides a MySQL-based triplestore with SPARQL support. Feature-wise, ARC2 is now in a stable state with no further feature additions planned. Issues are still being fixed and Pull Requests are welcome, though.
- EasyRdf - A PHP library designed to make it easy to consume and produce RDF. Symfony.
Python
JavaScript
- Sgvizler - javascript that renders the result of SPARQL SELECT queries into charts or html elements. It is cool stuff (ivan_herman, timbl).
Tools
- RDF Translator - a multi-format conversion tool for structured markup. It provides translations between data formats ranging from RDF/XML to RDFa or Microdata. The service allows for conversions triggered either by URI or by direct text input. Furthermore it comes with a straightforward REST API for developers.
- Simple javascript RDF Parser and query thingy - designed to run in a web-browser or SVG browser, allowing you to process RDF on the client. The parser isn't complete, there's no support for various bits of the spec, and isn't all that fast, especially with large XML/RDF files. I've found it quite useful though for simple querying.
- RDFaCE - A Semantic content editor based on TinyMCE WYSIWYG editor. RDFaCE is created as a proof of concept for WYSIWYM (What You See Is What You Mean) concept. WYSIWYM aims to enable end-users to easily annotate their content using RDFa and Microdata markups. RDFaCE employs external NLP APIs to suggest namespaces, properties, URIs and to automatically annotate content.
- W3C: ConverterToRdf - converts application data from an application-specific format into RDF for use with RDF tools and integration with other data. Converters may be part of a one-time migration effort, or part of a running system which provides a semantic web view of a given application.
- Redland - a set of free software C libraries that provide support for the Resource Description Framework (RDF).
- Raptor is a free software / Open Source C library that provides a set of parsers and serializers that generate Resource Description Framework (RDF) triples by parsing syntaxes or serialize the triples into a syntax. The supported parsing syntaxes are RDF/XML, N-Quads, N-Triples, TRiG, Turtle, RDFa 1.0 and 1.1, RSS tag soup including all versions of RSS, Atom 1.0 and 0.3, GRDDL and microformats for HTML, XHTML and XML. The serializing syntaxes are RDF/XML (regular, and abbreviated), Atom 1.0, GraphViz, JSON, N-Quads, N-Triples, RSS 1.0 and XMP.
- rdfstore-js is a pure Javascript implementation of a RDF graph store with support for the SPARQL query and data manipulation language. node.js
- CumulusRDF - an RDF store on cloud-based architectures. CumulusRDF provides a REST-based API with CRUD operations to manage RDF data. The current version uses Apache Cassandra as storage backend. A previous version is built on Google's AppEngine. CumulusRDF is licensed under GNU Affero General Public License.
- Graphite - a PHP Library, built on top of ARC2, to make it easy to do stuff with RDF data really quickly, without having to naff around with databases. It is not intended to be scalable, or a way of authoring RDF data. [
- Q&D RDF Browser is powered by Graphite and ARC2 and hosted by ECS at the University of Southampton.
- tFacet applies known interaction concepts to allow hierarchical faceted exploration of RDF data. Adobe Flex.
- http://www.visualdataweb.org/relfinder.php
- http://www.visualdataweb.org/semlens.php
- http://www.visualdataweb.org/gfacet.php
- prefix.cc - namespace lookup for RDF developers
- Graphity is an out-of-the-box solution for Linked Data publishing and rapid development of user-friendly Linked Data applications.
- Apache Jena - A free and open source Java framework for building Semantic Web and Linked Data applications.
Tabulator
- Tabulator is a generic data browser and editor. Using outline and table modes, it provides a way to browse RDF data on the web. RDF is the standard for inter-application data exchange.
RWW.IO
- RWW.IO - a personal Linked Data store, intended to be used as a backend service for your Linked Data applications, and it supports the latest standards and recommendations: RDF, JSON-LD, SPARQL 1.1 Update, WebID. All data stores (endpoints) interpret the HTTP request URI as the base URI for RDF operations and the default-graph URI for SPARQL operations. When using the service as a backend, you need to follwo two basic rules: Specify the media type of your request data with a Content-Type HTTP header. Specify your response type preference with an Accept HTTP header.
Other
See also MediaWiki#Semantic
- Apache Jena - A free and open source Java framework for building Semantic Web and Linked Data applications.
- PublishMyData is a Linked Data publishing platform. It lets you serve your 5-star Open Data on the web in a format that’s easy to understand, but it’s also machine readable so data experts can exploit it.
- Virtuoso is an innovative enterprise grade multi-model data server for agile enterprises & individuals. It delivers an unrivaled platform agnostic solution for data management, access, and integration.
- URIBurner - A data virtualization service that transforms data hosted in a variety of data spaces and formats into standards compliant Linked Data Objects for uniform access, integration and management. The underlying technology is Virtuoso's in-built Linked Data Middleware (aka Sponger) that uses URLs as data source names for its powerful data ingestion and transformation services that result in highly navigable Linked Data Object graphs. Post transformation, each Data Object is endowed with a dereferenceable identifier (Name) that resolves to its actual representation via its URL (Address). The Sponger then re-presents Data Object descriptions via HTML documents (the default behavior) or in a variety of raw data graph forms that include: CSV, N-Triples, Turtle, N3, RDF/XML, JSON, CXML, OData (Atom and JSON) etc.
- Disco - Hyperdata Browser is a simple browser for navigating the Semantic Web as an unbound set of data sources. The browser renders all information, that it can find on the Semantic Web about a specific resource, as an HTML page. This resource description contains hyperlinks that allow you to navigate between resources. While you move from resource to resource, the browser dynamically retrieves information by dereferencing HTTP URIs and by following rdfs:seeAlso links.
- http://linkeddata.uriburner.com/about/html/http://linkeddata.uriburner.com/about/id/entity/http/www4.wiwiss.fu-berlin.de/rdf_browser/%01dfdd7716dd407d1986431f6511842236
- CubicWeb Semantic Web Framework - a semantic web application framework, licensed under the LGPL, that empowers developers to efficiently build web applications by reusing components (called cubes) and following the well known object-oriented design principles.Its main features are: an engine driven by the explicit data model of the application, a query language named RQL similar to W3C’s SPARQL, a selection+view mechanism for semi-automatic XHTML/XML/JSON/text generation, a library of reusable components (data model and views) that fulfill common needs, the power and flexibility of the Python programming language, the reliability of SQL databases, LDAP directories, Subversion and Mercurial for storage backends.
- https://addons.mozilla.org/en-US/firefox/addon/linked-data-browser - detects RDF data, whether attached to a web page, served as-is, or available through content negotiation; and renders its through user-defined views.
- https://pypi.org/project/ontogram/ - Ontogram is an OWL ontology diagram generator.
- https://github.com/ontop/ontop - a platform to query relational databases as Virtual RDF Knowledge Graphs using SPARQL