Open social
Movements and initiatives
See also Feeds, WebDev#API, HTTP, Semantic web, Chat, Net media, Open data, Mesh
massively jumbled atm, to iron out order, etc.
- https://en.wikipedia.org/wiki/Comparison_of_software_and_protocols_for_distributed_social_networking
- Social Web Protocols - The Social Web Protocols are a collection of standards which enable various aspects of decentralised social interaction on the Web. This document describes the purposes of each, and how they fit together. Pre SOLID.
- Decentralized Social Networks - Jay Graber - Medium - Comparing federated and peer-to-peer protocols
- https://github.com/redecentralize/alternative-internet - A collection of interesting new networks and tech aiming at decentralisation (in some form).
- Granary - Fetches and converts data between social networks, HTML and JSON with microformats2, ActivityStreams 1 and 2 (including ActivityPub), Atom, RSS, JSON Feed, and more.
OASIS
1993-
- https://en.wikipedia.org/wiki/OASIS_(organization) - a global nonprofit consortium that works on the development, convergence, and adoption of standards for security, Internet of Things, energy, content technologies, emergency management, and other areas. OASIS was founded under the name "SGML Open" in 1993. It began as a trade association of SGML tool vendors to cooperatively promote the adoption of the Standard Generalized Markup Language (SGML) through mainly educational activities, though some amount of technical activity was also pursued including an update of the CALS
- OASIS Content Management Interoperability Services (CMIS) TC | OASIS - Using Web services and Web 2.0 interfaces to enable information sharing across content management repositories from different vendors
GMPG
2003
- Reference Model for Service Oriented Architecture v1.0 - This Reference Model for Service Oriented Architecture is an abstract framework for understanding significant entities and relationships between them within a service-oriented environment, and for the development of consistent standards or specifications supporting that environment. It is based on unifying concepts of SOA and may be used by architects developing specific service oriented architectures or in training and explaining SOA. A reference model is not directly tied to any standards, technologies or other concrete implementation details. It does seek to provide a common semantics that can be used unambiguously across and between different implementations. The relationship between the Reference Model and particular architectures, technologies and other aspects of SOA is illustrated in Figure 1. While service-orientation may be a popular concept found in a broad variety of applications, this reference model focuses on the field of software architecture. The concepts and relationships described may apply to other "service" environments; however, this specification makes no attempt to completely account for use outside of the software domain.
Semantic Social Web
- https://en.wikipedia.org/wiki/Social_Semantic_Web - developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.
OpenSocial
2007
- OpenSocial is the industry's leading and most mature standards-based component model for cloud based social apps.
- Wikipedia:OpenSocial is a public specification that defines a component hosting environment (container) and a set of common application programming interfaces (APIs) for web-based applications. Initially it was designed for social network applications and was developed by Google along with MySpace and a number of other social networks. In more recent times it has become adopted as a general use runtime environment for allowing untrusted and partially trusted components from third parties to run in an existing web application. The OpenSocial Foundation has also moved to integrate or support numerous other open web technologies. This includes Oauth and OAuth 2.0, Activity Streams, and portable contacts, among others.
DiSo
December 2007
- DiSo Project (dee • soh) is an initiative to facilitate the creation of open, non-proprietary and interoperable building blocks for the decentralized social web. Silo free living. Social networks are becoming more open, more interconnected, and more distributed. Many of us in the web creation world are embracing and promoting web standards — both client-side and server-side. Microformats, standard APIs, and open-source software are key building blocks of these technologies. This model can be described as having three sides: Information, Identity, and Interaction. Our first target is WordPress, bootstrapping on existing work and building out from there.
- http://wiki.factoryjoe.com/w/page/12283844/DistributedSocialNetwork
- http://factoryjoe.com/blog/2007/12/06/oauth-10-openid-20-and-up-next-diso/
DataPortability
November 2007
- Data portability is the ability for people to reuse their data across interoperable applications. The DataPortability Project works to advance this vision by identifying, contextualizing and promoting efforts in the space.
"There are numerous open standards that are considered to advance the vision, such as RDF, RDFa, microformats, APML, FOAF, OAuth, OpenID, OPML, RSS, SIOC, the XHTML Friends Network (XFN), XRI, and XDI."
- http://hueniverse.com/2007/12/reflections-on-the-open-web-community/
- http://techcrunch.com/2008/05/05/twitter-can-be-liberated-heres-how/
- http://www.niallkennedy.com/blog/2008/01/data-portability-authentication-authorization.html
- http://web.archive.org/web/20100706024305/http://2008.xtech.org/public/schedule/detail/565 - Data Portability with SIOC and FOAF. May 2008.
- http://web.archive.org/web/20110516032810/http://www.semanticscripting.org/SFSW2008/papers/11.pdf
- http://web.archive.org/web/20090414050007/http://faradaymedia.com/syncstream
- http://www.johnbreslin.com/blog/2008/05/09/prototype-for-distributed-decentralised-microblogging-using-semantics/
- http://forrester.typepad.com/groundswell/2008/01/the-open-social.html
- http://mrtopf.de/blog/plone/what-is-the-future-of-content-management-systems-related-to-social-networks/
- http://www.mediamatic.net/26386/en/federating-social-networks-the-technology
- http://www.mediamatic.net/26605/en/federating-social-networks
- http://ralphm.net/publications/berlin_2007/
- http://chrissaad.wordpress.com/2008/12/01/facebook-connect-aka-hailstorm-20/
- http://news.cnet.com/8301-17939_109-10111404-2.html
Drupal related
misc. old
- http://groups.google.com/group/openid
- http://groups.google.com/group/dataportability-public
- http://groups.google.com/group/diso-project
- http://groups.google.com/group/oauth
- http://groups.google.com/group/activity-streams/
- http://groups.google.com/group/ostatus-discuss
- http://groups.google.com/group/federated-social-web
- http://groups.google.com/group/open-web-discuss
- http://groups.drupal.org/microformats-in-drupal
- http://groups.drupal.org/activity
- http://groups.drupal.org/semantic-web
rssCloud
2009
- HowTo: Rebooting the RSS cloud - There are three sides to the cloud:1. The authoring tool. I edit and update a feed. It contains a <cloud> element that says how a subscriber should request to notification of updates.2. The cloud. It is notified of an update, and then in turn notifies all subscribers.3. The subscriber. A feed reader, aggregator, whatever -- that subscribes to feeds that may or may not be part of a cloud.
"There are three sides to the cloud:
- 1. The authoring tool. I edit and update a feed. It contains a <cloud> element that says how a subscriber should request to notification of updates.
- 2. The cloud. It is notified of an update, and then in turn notifies all subscribers.
- 3. The subscriber. A feed reader, aggregator, whatever -- that subscribes to feeds that may or may not be part of a cloud.
- HowTo: Implementor's guide to rssCloud - Dave Winer
Federated Social Web
2009-2013-..
- W3C Social Web Incubator Group - This XG started on 6 April 2009 and closed on 6 December 2010. See the final report.The mission of the Social Web Incubator Group, part of the Incubator Activity, is to understand the systems and technologies that permit the description and identification of people, groups, organizations, and user-generated content in extensible and privacy-respecting ways.
- A Standards-based, Open and Privacy-aware Social Web - The Social Web is a set of relationships that link together people over the Web. The Web is an universal and open space of information where every item of interest can be identified with a URI. While the best known current social networking sites on the Web limit themselves to relationships between people with accounts on a single site, the Social Web should extend across the entire Web. Just as people can call each other no matter which telephone provider they belong to, just as email allows people to send messages to each other irrespective of their e-mail provider, and just as the Web allows links to any website, so the Social Web should allow people to create networks of relationships across the entire Web, while giving people the ability to control their own privacy and data. The standards that enable this should be open and royalty-free. We present a framework for understanding the Social Web and the relevant standards (from both within and outside the W3C) in this report, and conclude by proposing a strategy for making the Social Web a "first-class citizen" of the Web.
- FinalReport - Social Web XG Wiki - This document is the final report of the W3C Social Web Incubator Group. This report presents systems and technologies that are working towards enabling a Social Web, and is followed by a strategy for standardizing this work in order to ensure the Social Web is open, decentralized, and royalty-free. This report focuses on work that permits the description and identification of people, groups, organizations, as well as user-generated content in extensible and privacy-respecting ways. This report describes a common framework for the concepts behind the Social Web and the state of the art in 2010, including current technologies and standards. We conclude with an analysis of where future research and standardization will benefit users and the entire Social Web ecosystem's growth. We also suggest a strategy for the role of the W3C in the Social Web.
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/Protocols - OStatus, Activity Streams, Apache Wave (former Google Wave), DSNP, DFRN, OAuth, oEmbed, OExchange, Open Graph Protocol, OpenID, OpenPGP, OpenSocial, PubSubHubbub, RSSCloud, RSSN, Salmon, Tent, Webfinger, WebID, XMPP
- we (@daveman692 @evanpro + I) just came up with a #fsws Social Web Acid Test (SWAT) v0 draft. full description, challenge: user A takes a photo of B from their phone and posts it, B gets notified that they are in a photo, C who follows A gets the photo and leaves a comment, A and B get notified of the comment, where users are on at least 2 (ideally 3) different services each of which is built with a different code base. drafted here: http://federatedsocialweb.net/wiki/FSWS2010_Next_Meeting_and_FSWS2011 - challenge: 2+ pieces of software that pass this test by 2010-09-30. - Tantek - challenge: user A takes a photo of B from their phone and posts it, B gets notified that they are in a photo, C who follows A gets the photo and leaves a comment, A and B get notified of the comment, where users are on at least 2 (ideally 3) different services each of which is built with a different code base.
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/SWAT0 - an integration use case for the federated social web.
- W3C Federated Social Web Incubator Group - This XG started on 15 December 2010 and transitioned on 12 January 2012 to Federated Social Web Community Group. The mission of the Federated Social Web Incubator Group, part of the Incubator Activity, is to provide a set of community-driven specifications and a test-case suite for a federated social web.
- Planet Federated Social Web - archived
- Federated Social Web Community Group - closed on 2019-03-13 - see also the Social Web Incubator Community Group. This group continues the work of the W3C Federated Social Web Incubator Group (http://www.w3.org/2005/Incubator/federatedsocialweb/)
- Socially aware cloud storage - Design Issues - There is an architecture in which a few existing or Web protocols are gathered together with some glue to make a world wide system in which applications (desktop or Web Application) can work on top of a layer of commodity read-write storage. Crucial design issues are that principals (users) and groups are identifies by URIs, and so are global in scope, and that elements of storage are access controlled using those global identifiers. The result is that storage becomes a commodity, independent of the application running on it.
- PDF: An Architecture of a Distributed Semantic Social Network - Online social networking has become one of the most popular services on the Web. However, current social networks are like walled gardens in which users do not have full control over their data, are bound to specific usage terms of the social network operator and suffer from a lock-in effect due to the lack of interoperability and standards compliance between social networks. In this paper we propose an architecture for an open, distributed social network, which is built solely on Semantic Web standards and emerging best practices. Our architecture combines vocabularies and protocols such as WebID, FOAF, Se-mantic Pingback and PubSubHubbub into a coherent distributed semantic social network, which is capable to provide all crucial functionalities known from centralized social networks. We present our reference implementation, which utilizes the OntoWiki application framework and take this framework as the basis for an extensive evaluation. Our results show that a distributed social network is feasible, while it also avoids the limitations of centralized solutions
- Read Write Web Community Group - The activity of this group is to apply Web standards to trusted read and write operations.
- https://github.com/read-write-web/rww-play - an implementation in Play of a number of tools to build a Read-Write-Web server using Play2.x and akka. It is very early stages at present and it implements sketches of the following A CORS proxy An initial implementation of Linked Data Basic Profile
- http://www.w3.org/community/fedid - Sep 2 2013
OStatus / StatusNet
via Identi.ca, 2008
- http://en.wikipedia.org/wiki/OpenMicroBlogging - prior system
- OStatus is an open standard for distributed status updates that references a suite of open protocols including Atom, Activity Streams, PubSubHubbub, Salmon, Webfinger, that allows different messaging hubs to route status updates between users in near real-time. - 2010
- Status.net - formerly Laconica, powered Identica
- http://p2pfoundation.net/Social_Publishing_with_Drupal
- http://www.istos.it/blog/social-network/supporting-activity-streams-drupal
- http://status.net/2010/07/21/federated-social-web-summit-wrapup
- http://evan.prodromou.name/files/fedsocweb/fedsocweb.html
- http://www.devcomments.com/OpenSocial-and-OStatus-at246411.htm
august 2010
- http://groups.google.com/group/ostatus-discuss/browse_thread/thread/329e440ed44131f9
- http://www.istos.it/blog/federated-social-web/federated-social-web-and-drupal-notes-drupalcon-bof-meeting
aug 2013; @tantek | previous efforts at directly designing decentralized protocols (without selfdogfood) always result in overly complex protocols that not enough people can implement. e.g. Salmon
- https://e14n.com/evan/note/5JFFMeYMQKiuzPtSYgRoYw - move to pump.io
now part of GNU Social
- https://github.com/emersion/go-ostatus - An OStatus library written in Go
pump.io
2012, succeeds OStatus / StatusNet
- http://pump.io/ - successor to StatusNet, a general-purpose Activity Streams engine. It diverges from OStatus in a few other respects, of course, such as sending activity messages as JSON rather than as Atom, and by defining a simple REST inbox API instead of using PubSubHubbub and Salmon to push messages to other servers. Pump.io also uses a new database abstraction layer called Databank, which has drivers for a variety of NoSQL databases, but supports real relational databases, too. StatusNet, in contrast, was bound closely to MySQL. But, in the end, the important thing is the feature set; a pump.io instance can generate a microblogging feed, an image stream, or essentially any other type of feed. Activity Streams defines actions (which are called "verbs") that handle common social networking interaction; pump.io merely sends and receives them.
- http://www.skilledtests.com/wiki/Pump.io
- http://www.h-online.com/open/news/item/StatusNet-transforms-into-Node-js-driven-pump-io-1771646.html
- http://opensource.com/life/13/7/pump-io
- LWN.net: StatusNet, Identi.ca, and transitioning to pump.io - 2013
- Identi.ca - This site runs pump.io, the high-performance Open Source social engine. It pumps your life in and out of your friends, family and colleagues.
- https://github.com/pump-io/pump.io/issues/8 - "We should support remote follow using OStatus.", 2012
#indieweb
- IndieWeb - a community of independent & personal websites connected by simple standards, based on the principles of: owning your domain & using it as your primary identity, publishing on your own site (optionally syndicating elsewhere), and owning your data. [4]
indieauth, activitystrea.ms, RSSB, etc.
- Indie Map - a public IndieWeb social graph and dataset.
- http://indieweb.com/IndieMark - like fedsocwebs SWAT* benchmarks
- http://werd.io/entry/51dca7e2bed7de945debf707/the-indieweb-as-a-minimum-viable-social-web-ecosystem
- http://www.wired.com/wiredenterprise/2013/08/indie-web/
- http://tantek.com/2013/113/b1/first-federated-indieweb-comment-thread
- http://bret.io/2013/06/28/indiewebcamp-2013-roundup/
- ActivityPush - A lightweight method for URI addressable resources to be automatically notified about remote (off-site) activites on them. A crypto-free alternative to the Salmon Protocol for public activites.
- Bridgy - adds social media reactions to posts on your web site. It can also cross-post from your site to social networks. And more!
- https://github.com/snarfed/bridgy - Connects your web site to social media. Likes, retweets, mentions, cross-posting, and more...
- Bridgy Fed - Got an IndieWeb site? Want to interact with Mastodon, Hubzilla, and the rest of the fediverse? Bridgy Fed is for you.
Projects
Known
- Known - gives you full control. Host your site on our service, or install it on your own server and extend it to meet your needs. The core Known platform is open source, and it is designed to be easy to customize, redesign, and build on top of.
Dark Matter
- Dark Matter - A personal publishing platform for the #indieweb
helloworld
- https://github.com/mimecuvalo/helloworld - federated social web tumblr/blog/rss reader/wordpress-like thingy. passes swat0!
dobrado
- dobrado - a flexible content management system written in PHP & Javascript. It's currently being developed by Malcolm Blaney. It can be installed by copying a single file to your web server and following the prompts. The only other requirement is a MySQL database, which needs to be created before starting the install process. When the install is complete you will also be able to configure automatic updates so that your version of the software stays up to date. If you're interested in following software changes you can subscribe to the updates feed.
- i.haza.website - Create a website and let's make the web fun again! ...or maybe fun for the first time! This website helps you create your own, personal website that you can use for writing, sharing and responding to others. Your website can become a little piece of the social web that you get to control.
Koype
- Koype - provides people with software that allows them to own their social data on the Web and determine who gets to do what with it.
- * Koype: Humane Social Networking - provides people with software that allows them to own their social data on the Web and determine who gets to do what with it.
onesocialweb
2011?
Tent
2012
- Tent - the protocol for decentralized communication. Tent uses HTTPS and JSON to transport posts between servers and apps.
- Tent - use data and posts across your apps and send and receive posts from friends. Right now, most people use Tent to share short 256 character long status posts with friends. Many independent developers are building other apps that use the Tent protocol.
- https://cupcake.io - service
App.net
2012
- http://app.net - $ish ecosystem
- http://aaronparecki.com/articles/2013/03/31/1/a-response-to-replies-i-received-on-my-post-an-open-challenge-to-app-net
- http://blog.app.net/2013/08/07/response-to-brennan-novak-part-ii/
ActivityPub
- ActivityPub - The ActivityPub protocol is a decentralized social networking protocol based upon the [ActivityStreams] 2.0 data format. It provides a client to server API for creating, updating and deleting content, as well as a federated server to server API for delivering notifications and content.
- https://en.wikipedia.org/wiki/ActivityPub - an open, decentralized social networking protocol based on Pump.io's ActivityPump protocol. It provides a client/server API for creating, updating and deleting content, as well as a federated server-to-server API for delivering notifications and content.
- https://www.w3.org/TR/activitystreams-core - In the most basic sense, an "Activity" is a semantic description of an action. It is the goal of this specification to provide a JSON-based syntax that is sufficient to express metadata about activities in a rich, human-friendly but machine-processable and extensible manner. This can include constructing natural-language descriptions or visual representations about the activity, associating actionable information with various types of objects, communicating or recording activity logs, or delegation of potential actions to other applications.
- https://www.w3.org/ns/activitystreams - This document lists the terms used for the ActivityStreams 2.0 protocol and its stable extensions, and provides a namespace so each term has an HTTP IRI.
- Activity Vocabulary - This specification describes the Activity vocabulary. It is intended to be used in the context of the ActivityStreams 2.0 format and provides a foundational vocabulary for activity structures, and specific activity types.
- https://github.com/swicg/activitystreams2-owl - A non-normative turtle-formatted ontology version of the Activity Streams 2.0 vocabulary
- lwn.net: Federation in social networks
- https://github.com/BasixKOR/awesome-activitypub - Curated list of ActivityPub-based Projects
- https://github.com/writeas/Read.as - Free and open source long-form reader.
- Go-Fed - canonical resource for tutorials and documentation surrounding the go-fed organization.
- https://codeberg.org/fediverse/delightful-activitypub-development - A curated list of resources for ActivityPub developers who create software for the Fediverse.
PeerTube
- https://github.com/Chocobozzz/PeerTube - Federated (ActivityPub) video streaming platform using P2P (BitTorrent) directly in the web browser with WebTorrent and Angular.
- Sepia Search - A search engine of PeerTube videos and channels. Developed by Framasoft
Plume
- Plume - Federated blogging engine, based on ActivityPub. It uses the Rocket framework, and Diesel to interact with the database. [10]
Nautilus
- https://github.com/aaronpk/Nautilus - meant to run as a standalone service to deliver posts from your own website to ActivityPub followers. You can run your own website at your own domain, and this service can handle the ActivityPub-specific pieces needed to let people follow your own website from Mastodon or other compatible services.
Honk
- honk - Take control of your honks and join the federation. An ActivityPub server with minimal setup and support costs. Spend more time using the software and less time operating it. No attention mining. No likes, no faves, no polls, no stars, no claps, no counts. Purple color scheme. Custom emus. Memes too. Avatars automatically assigned by the NSA. The button to submit a new honk says "it's gonna be honked". The honk mission is to work well if it's what you want. This does not imply the goal is to be what you want.
Fediverse
GNU Social, Hubzilla, PostActiv, Friendica, Mastodon, Pleroma, etc.
- https://en.wikipedia.org/wiki/Fediverse - portmanteau of "federation" and "universe", is an ensemble of social networks, which, while independently hosted, can communicate with each other. ActivityPub, a W3C standard, is the most widely used protocol that powers the fediverse. Users on different websites can send and receive updates from others across the network. Noted fediverse platforms include Mastodon, Lemmy, PeerTube, and Pixelfed. Nearly all fediverse platforms are free and open-source software.
The term "fediverse" was first used to describe the network formed by software using the OStatus protocol, such as GNU Social, Mastodon, and Friendica. In January 2018, the W3C presented the ActivityPub protocol, aiming to improve the interoperability between different software packages run on a wide network of servers. By 2019, a majority of software that was previously using OStatus had switched to ActivityPub, and the term "fediverse" came to refer to the ActivityPub-based federated network.
- the federation - statistics about nodes in the fediverse. Depending on the project, exposed statistics might have to be activated separately. To appear on this list, the node needs to be registered on this site separately, either manually or extracted from another list of nodes.
- https://git.sr.ht/~pierrenn/twitter_escape - A bunch of python scripts to extract fediverse addresses from your twitter account.
- Fedigardens - Enjoy a simplified, discussion-driven experience for Mastodon on iPhone and iPad.
- https://github.com/timbray/fedi-uri - describes the "fedi" URI scheme. The posts and accounts that populate the Fediverse, and certain other constructs such as hashtags, are "resources" in the sense described by RFC3986. Since they are normally accessed over HTTP and HTTPS transports, they are conventionally identified by "https" URIs. However, the process by which Fediverse resources are retrieved and presented to users is more complex than a straightforward HTTPS request. The presence of the "fedi" scheme signals that this more complex process is appropriate.
Mastodon
- The Mastodon Project - Giving social networking back to you
Lemmy
- Lemmy - a selfhosted social link aggregation and discussion platform. It is completely free and open, and not controlled by any company. This means that there is no advertising, tracking, or secret algorithms. Content is organized into communities, so it is easy to subscribe to topics that you are interested in, and ignore others. Voting is used to bring the most interesting items to the top.
- Sync for Lemmy - Lemmy.world - Android app
- Nightmare on Lemmy Street (A Fediverse GDPR Horror Story) - Michael Altfield's Tech Blog - tl;dr I (accidentally) uploaded a photo of my State-issued ID to Lemmy, and I couldn't delete it.
- https://github.com/maltfield/awesome-lemmy-instances - Comparison of different Lemmy Instances [20]
- feddit.org - a German and English-speaking Lemmy community that evolved from feddit.de. Feddit.org serves as a Reddit alternative in the Fediverse. We see ourselves as a self-determined space, outside the control of commercial tech companies.
Pixelfed
- Pixelfed - free, federated and ethical photo sharing social media platform.
GangGo
- GangGo - a decentralized social network written in GoLang. It uses the same federation library like Diaspora, Mastodon and therefore can participate in conversations like any other Pod!
Prismo
- Prismo - a new link-sharing platform intended to work similarly to Reddit, Lobst.ers, or Hacker News. Michał Bajur, creator of Mastodon Tags Explorer, is building the platform for the fediverse, meaning that it speaks the ActivityPub protocol and is intended to work with other federated parts of the ecosystem.
- https://gitlab.com/prismosuite/prismo - Federated link aggregation powered by ActivityPub. Ruby.
Hyperspace
- Hyperspace - the fluffiest client for Mastodon and other fediverse networks written in TypeScript and React. Hyperspace offers a fun, clean, fast, and responsive design that scales beautifully across devices and enhances the fediverse experience.
bookwyrm
- https://github.com/mouse-reeve/bookwyrm - Social reading and reviewing, decentralized with ActivityPub
Spritely
- Spritely - a project to level up the federated social web. It builds on our experience from co-authoring ActivityPub, the largest decentralized social network on the web to date, while applying lesser known but powerful ideas from the object capability security community.Spritely consists of a number of modular components bringing new and rich features, from distributed programming, to decentralized storage, to virtual worlds.Better worlds await, because better worlds are possible. We all deserve freedom of communication. Why not make the journey fun in the process?
Dolphin
- https://github.com/syuilo/dolphin - a lightweight ActivityPub server for personal (or team).
Epicyon
- Epicyon ActivityPub server - an AGPL licensed ActivityPub protocol compliant federated social network server suitable for hosting a small number of accounts on low power systems requiring minimal maintenance, such as single board computers. It's the ActivityPub equivalent of an email server, storing posts as human readable JSON on file, rather than in a database. It also uses only a small amount of RAM.An Internet of People, Not Corporate Agendas. Epicyon is written in Python with a HTML+CSS web interface and uses no javascript which makes display in a web browser very lightweight. It can run as a Progressive Web App on mobile. Just say "no" to boring social media sites packed with generic adverts and zombified corporate influencers.
Bonfire
- Bonfire - a modular ecosystem for federated networks. The project creates interoperable toolkits that people can use to easily build their own apps to meet their specific needs. Users are then free to interact with multiple people and groups using these apps hosted on their own device, regardless of what federated software these other people use. Federated topics within the Bonfire ecosystem can consist of a hashtag, a category in a taxonomy, a location, etc. This enables users to find a topic they are interested in, see everything that was tagged with that (publicly or in their network), and follow it to receive any new tagged content. This will be interoperable with existing fediverse apps like Mastodon without requiring extra development on their end, and will create a decentralised graph of topics that can help relevant information flow from instance to instance. All content on a Bonfire instance (including remote content coming in via follows or federated topics) will also be aggregated in a local search index with which the user can search their own data, information from people or groups they follow, as well as content from topics or locations they are interested in from around the fediverse. This search will happen locally on their device (which is a plus for privacy), with results appearing instantly while typing a query, and being able to filter the results (e.g., by object or activity type, hashtags, topics, or language). Every line of Bonfire’s code is available to be used or forked, in a collection of libraries that can be assembled and re-assembled to create all kinds of full-featured apps. One example is Bonfire's mutual aid extension where users can post and search for requests and offers across different instances according to topic and/or geographical location.
Misskey
- Misskey - a decentralized and open source microblogging platform. It has "Reactions" that allow you to easily express your feeling, "Drive" that allow you to manage files in one place, and a highly customizable UI that makes it more fun to share something.Misskey also implements ActivityPub, so it can communicate with other platforms interactively. Since the code is open to the public, users can also create their own instances and create their own communities. Because Misskey uses Node.js, a non-blocking IO, performance remains lightweight even when federating with many instances.From the very beginning of its development, Misskey has been focused on being the first to incorporate the latest technologies of the web to provide an unique experience.
GoToSocial
- GoToSocial - provides a lightweight, customizable, and safety-focused entryway into the Fediverse, and is comparable to (but distinct from) existing projects such as Mastodon, Pleroma, Friendica, and PixelFed. GoToSocial is still ALPHA SOFTWARE. It is already deployable and useable, and it federates cleanly with many other Fediverse servers (not yet all). However, many things are not yet implemented, and there are plenty of bugs! We foresee entering beta around the beginning of 2024.
- https://github.com/superseriousbusiness/gotosocial - an ActivityPub social network server, written in Golang. With GoToSocial, you can keep in touch with your friends, post, read, and share images and articles. All without being tracked or advertised to!
Kitsune
- Kitsune - an open-source social media server utilising the ActivityPub protocol. Utilising the capabilities of ActivityPub, you can interact with people on Mastodon, Misskey, Akkoma, etc. Due to its decentralised nature, you can self-host Kitsune on your own hardware and still interact with everyone! Kitsune itself is pretty lightweight and should run even on a Raspberry Pi (even though we haven't tested that yet).
Solid
- Solid - a specification that lets people store their data securely in decentralized data stores called Pods. Pods are like secure personal web servers for data. When data is stored in someone's Pod, they control which people and applications can access it.
- https://github.com/solid/solid - Solid (derived from "social linked data") is a proposed set of conventions and tools for building decentralized Web applications based on Linked Data principles. Solid is modular and extensible. It relies as much as possible on existing W3C standards and protocols. [21]
- Solid Community Group - The aims of the Solid project are in line with those of the Web itself: empowerment towards an equitable, informed and interconnected society. Solid adds to existing Web standards to realise a space where individuals can maintain their autonomy, control their data and privacy, and choose applications and services to fulfil their needs. The mission of the Solid Community Group is to describe the interoperability between different classes of products by using Web communication protocols, global identifiers, authentication and authorization mechanisms, data formats and shapes, notifications, and query interfaces. To contribute towards a net positive social benefit, we use the Ethical Web Principles to orient ourselves. The consensus on the technical designs are informed by common use cases, implementation experience, and use. Solid Technical Reports lists Work Items, information on how to Participate, and the Solid of Code of Conduct (in addition to the Positive Work Environment at W3C: Code of Ethics and Professional Conduct.)
- https://en.wikipedia.org/wiki/Solid_(web_decentralization_project) - Social Linked Data, is a web decentralization project led by Sir Tim Berners-Lee, the inventor of the World Wide Web, originally developed collaboratively at the Massachusetts Institute of Technology (MIT). The project "aims to radically change the way Web applications work today, resulting in true data ownership as well as improved privacy" by developing a platform for linked-data applications that are completely decentralized and fully under users' control rather than controlled by other entities. The ultimate goal of Solid is to allow users to have full control of their own data, including access control and storage location. To that end, Tim Berners-Lee formed a company called Inrupt to help build a commercial ecosystem to fuel Solid.
- Social Linked Data - An introduction to the Solid project. Slides.
- Solid Hacks - Solid Hacks - This book covers but a fraction of what is possible in solid. It hopefully illustrates some interesting tips and tricks.
- Co-operating Systems - a social enterprise that researches, develops, maintains and provides services around an open source/open standards software platform to enable co-operation among autonomous actors. Our stack takes a completely new approach: the web is the database and data is a web of relations. Apps using our libraries can follow relations through the web of data and write to any Social Linked Data server (SoLiD) if allowed. As a result designers will be able to write applications providing a consistent human interface for people needing to co-operate within and across organisations, each application tailored for the person viewing the data.
Specification
- Solid Technical Reports - The purpose of this document is to help readers orient themselves with the activities of the Solid CG. The Solid CG’s technical reports (TR) include specifications, use cases and requirements, best practices and guidelines, primers and notes about the Solid ecosystem.
- https://github.com/solid/specification - This repository contains the source code of the Solid specification, which aims to be a clear, unambiguous, and implementable rewrite of the Unofficial Draft.
- https://github.com/solid/solid-namespace - A collection of common RDF namespaces used in the Solid project
- Solid-OIDC - A key challenge on the path toward re-decentralizing user data on the Worldwide Web is the need to access multiple potentially untrusted resources servers securely. This document aims to address that challenge by building on top of current and future web standards, to allow entities to authenticate within a Solid ecosystem.
- https://github.com/jeff-zucker/specs2glossary - Gather & display terms from the Solid specifications
Community
- SOLIDARITY - A Solid based community discussion App.
Apps
- https://github.com/CommunitySolidServer/CommunitySolidServer - An open and modular implementation of the Solid specifications. The Community Solid Server is open software that provides you with a Solid Pod and identity. This Pod acts as your own personal storage space so you can share data with people and Solid applications.
- Solid Community Application Directory - Applications - Solid Community Forum] - The Solid Community Application Directory is a place where members of the Solid Community, from established companies to open source contributors, can share the applications they’ve created. To get your application added, create a new topic thread in this category, and populate the provided template. Once a submission receives approval from a moderator, it will be added to the listing. The community at large reviews applications in the listing. The more likes a listed application receives, the higher it will appear in the results. Top
- SolidWeb - a prototype implementation of a Solid server. It is a fully functional server, but there are no security or stability guarantees. If you have not already done so, please create an account.
- https://github.com/linkeddata/gold - a reference Linked Data Platform server for the Solid platform. Written in Go, based on initial work done by William Waites.
- https://github.com/solid/node-solid-server - Solid server on top of the file-system in NodeJS
- https://github.com/solid/test-suite - An automated test of Solid specification technical compliance
- https://github.com/solid/solid-cli - A utility to facilitate command-line interaction with Solid servers
- https://github.com/solid/solid-ui - User Interface widgets and utilities for SolidThese are HTML5 widgets which connect to a solid store. Building blocks for solid-based apps.
- https://github.com/linkeddata/warp
- https://github.com/linkeddata/profile-editor
- https://github.com/linkeddata/cimba
- https://github.com/linkeddata/app-schedule
- https://github.com/linkeddata/contacts
- https://github.com/mzereba/todo
- https://github.com/melvincarvalho/helloworld
- https://github.com/solid/mashlib - Solid-compatible data mashup library and Data Browser
- https://github.com/solid/userguide - userguide to data browser
- dokieli - a clientside editor for decentralised article publishing, annotations and social interactions. [24]
- https://github.com/jeff-zucker/solid-shell - a command-line and interactive shell for Solid
- Focus - task manager
- Pixolid - Pixolid is a Web application built to support the Solid framework. Its purpose is to manage, upload, comment, and like images via the Solid POD storage.
- https://gitlab.com/angelo-v/pod-homepage - A public homepage based on data in your Solid Pod.Load personal data from your Pod to display a nice homepageHost it on your Solid Pod or elsewhere
- https://github.com/jeff-zucker/data-kitchen - The solid databrowser technology as a stand-alone electron app
- https://github.com/jeff-zucker/solid-file-client - A Javascript library for creating and managing files and folders in Solid data stores
- Portal – Solid Home - POD index
- POD CHAT - Decentralized Messenger App For Solid POD's
- OpenLink Structured Data Editor - the OpenLink Structured Data Editor, is a tool for creating and editing structured data using RDF Language statements/triples, through many web browsers.OSDE enables creation and editing of data using abstract subject → predicate → object or entity → attribute → value notation.OSDE currently ingests RDF from documents serialized as RDF-Turtle, JSON-LD, and RDF/XML.Once constructed or edited, data can be saved to local or remote storage, or directly copied, as RDF-Turtle documents.Full RDF-Turtle document access requires that HTTP-accessible host servers support at least one of the following open standards — Linked Data Platform (LDP); WebDAV; SPARQL 1.1 Update; SPARQL Graph Protocol. Data stored as RDF-Turtle documents can be further transformed to other formats (JSON-LD, CSV, OData, Microdata, RDF/XML, RDF/JSON, etc.) using a variety of transformation tools and services.
- OpenLink Structured Data Sniffer Home Page - a browser extension for Google Chrome, Microsoft Edge, Mozilla Firefox, Opera, and Vivaldi (with a build planned for Apple Safari) that unveils structured metadata embedded within HTML documents and web pages.
- LaunchPad - A TrinPod™ is an Industrial strength Solid Pod with conceptual computing through Trinity AI Capable of handling a massive amount of data.
- Databox - BBC R&D - privacy-aware personal data container/manager and dashboard server
- Databox
- https://github.com/me-box/databox - an open-source personal networked device, augmented by cloud-hosted services, that collates, curates, and mediates access to an individual’s personal data by verified and audited third-party applications and services. The Databox will form the heart of an individual’s personal data processing ecosystem, providing a platform for managing secure access to data and enabling authorised third parties to provide the owner with authenticated services, including services that may be accessed while roaming outside the home environment. Databox project is led by Dr Hamed Haddadi (Imperial College) in collaboration with Dr Richard Mortier (University of Cambridge) and Professors Derek McAuley, Tom Rodden, Chris Greenhalgh, and Andy Crabtree (University of Nottingham) and funded by EPSRC.
Autonomous Data
- Introduction | Autonomous Data - an application architecture that respects users privacy and data ownership.Traditional architectures involve storing user data on service providers' servers. Even if they give ample control to their users, they are still acting as middlemen. In this situation, true data ownership cannot be more than a mirage.
- https://github.com/noeldemartin/kinko - Autonomous Data Server
- https://github.com/noeldemartin/focus - Autonomous Data Task Manager
IPFS
See Application#IPFS
Data Transfer Project
- Data Transfer Project - launched in 2018 to create an open-source, service-to-service data portability platform so that all individuals across the web could easily move their data between online service providers whenever they want. The contributors to the Data Transfer Project believe portability and interoperability are central to innovation. Making it easier for individuals to choose among services facilitates competition, empowers individuals to try new services and enables them to choose the offering that best suits their needs.Current contributors include:
Personium
- Personium - An interconnectable open source PDS (Personal Data Store) server envisioning world wide web of protected data APIs. [25]
m-ld
- m-ld - keeps information live and sharable.With m-ld, information is just local state, which is shared to where it's used—on mobiles, in browsers, in microservices, anywhere.At the heart of m-ld is a decentralised protocol for distributing live state among clones. Using m-ld, every app instance has read-write access to the shared information via its local clone, with zero network latency. Changes to the information are propagated to all other app instances, so they are all eventually consistent.
DWeb
Lbry
- Lbry - a new protocol that allows anyone to build apps that interact with digital content on the LBRY network. Apps built using the protocol allow creators to upload their work to the LBRY network of hosts (like BitTorrent), to set a price per stream or download (like iTunes) or give it away for free (like YouTube without ads). The work you publish could be videos, audio files, documents, or any other type of file.
Bluesky / AT Protocol
- Bluesky - a new foundation for public conversation and social networking which gives creators independence from platforms, developers the freedom to build, and users a choice in their experience.
- https://github.com/bluesky-social
- https://github.com/bluesky-social/social-app - The Bluesky Social application for Web, iOS, and Android
- Unofficial Bluesky roadmap - This is a list of all the issues open on the Bluesky app's GitHub repository that have a roadmap-related label.
- The AT Protocol - The AT Protocol is a networking technology created by Bluesky to power the next generation of social applications.
- https://github.com/bluesky-social/atproto - a working repository for the AT Protocol, aka the Authenticated Transfer Protocol.
- https://github.com/rFoxen/BlueskyModerationExtension - a Firefox extension that enhances moderation on Bluesky. It allows moderators to quickly block users, manage block lists, and enjoy engaging visual feedback during the blocking process.
- https://addons.mozilla.org/en-US/firefox/addon/share-on-bluesky - allows to instantly share web pages on Bluesky
as post embeds, without having autolink inside a post
- https://github.com/snarfed/lexrpc - Python implementation of AT Protocol's XRPC + Lexicon
- https://github.com/snarfed/arroba - Python implementation of Bluesky PDS and AT Protocol, including repo, MST, and sync methods
Identity / authentication
See also Net media#Identity
Ident
- https://en.wikipedia.org/wiki/Ident_protocol - specified in RFC 1413, is an Internet protocol that helps identify the user of a particular TCP connection. One popular daemon program for providing the ident service is identd.
- https://en.wikipedia.org/wiki/oidentd - an RFC 1413 compliant ident daemon which runs on Linux, FreeBSD, OpenBSD, NetBSD, DragonFly BSD, and some versions of Darwin and Solaris. It can handle IP masqueraded or NAT connections, and has a flexible mechanism for specifying ident responses. Users can be granted permission to specify their own ident responses, hide responses for connections owned by them, or return random ident responses. Responses can be specified according to host and port pairs. One of the most notable capabilities is spoofed ident responses or ident spoofing.
- https://github.com/InfrastructureServices/authd - a RFC 1413 ident protocol daemon
OpenID
2005
- OpenID is an open standard that allows users to be authenticated by certain co-operating sites (known as Relying Parties or RP) using a third party service, eliminating the need for webmasters to provide their own ad hoc systems and allowing users to consolidate their digital identities.
- http://wiki.openid.net/w/page/12995226/Run-your-own-identity-server
- https://drupal.org/project/openid_provider
- http://www.cse.wustl.edu/~jain/cse571-07/ftp/websso/
- http://tantek.com/2011/047/t1/indiewebcamp-with-openid-seriously-best-web-id
- http://stackoverflow.com/questions/1116743/where-can-i-find-a-list-of-openid-provider-urls
- http://meta.stackexchange.com/questions/31021/what-openid-providers-should-we-feature-on-the-login-page
OAuth
- OAuth - 2006-2010
- OAuth 2 - 2012
- OAuth 2.1 - 2020
- http://oauth.net - access granting protocol, silod pseudo-auth for identity and api access
OAuth began in November 2006 when Blaine Cook was developing the Twitter OpenID implementation. Meanwhile, Ma.gnolia needed a solution to allow its members with OpenIDs to authorize Dashboard Widgets to access their service. Cook, Chris Messina and Larry Halff from Ma.gnolia met with David Recordon to discuss using OpenID with the Twitter and Ma.gnolia APIs to delegate authentication. They concluded that there were no open standards for API access delegation.
The OAuth discussion group was created in April 2007, for the small group of implementers to write the draft proposal for an open protocol. DeWitt Clinton from Google learned of the OAuth project, and expressed his interest in supporting the effort. In July 2007 the team drafted an initial specification. Eran Hammer joined and coordinated the many OAuth contributions, creating a more formal specification. On October 3, 2007, the OAuth Core 1.0 final draft was released.
Because OAuth 2.0 is more like a framework rather than a defined protocol, any OAuth 2.0 implementation is unlikely to naturally be interoperable with any other OAuth 2.0 implementation. Further deployment profiling and specification is required for any interoperability.
- http://web.archive.org/web/20110305071413/http://blog.behindlogic.com/2007/12/oauth-is-key-to-future-longings-of.html
- http://homakov.blogspot.co.uk/2013/03/oauth1-oauth2-oauth.html
- http://hueniverse.com/2012/07/oauth-2-0-and-the-road-to-hell/
OpenID Connect / OIDC
2010
- http://factoryjoe.com/blog/2010/01/04/openid-connect/
- https://github.com/rohe/pyoidc
- OpenID Connect - Posted Jun 3, 2010
- http://factoryjoe.com/blog/2010/05/16/combing-openid-and-oauth-with-openid-connect
- http://nat.sakimura.org/2012/01/20/openid-connect-nutshell/
- http://nat.sakimura.org/2013/07/28/write-openid-connect-server-in-three-simple-steps/
- http://developer.studivz.net/wiki/index.php/OpenID_Connect
- http://osis.idcommons.net/wiki/Main_Page
- http://nat.sakimura.org/2013/07/28/write-openid-connect-server-in-three-simple-steps/
- http://nimbusds.com/blog/our-openid-connect-server/
- https://npmjs.org/package/openid-connect
- https://github.com/mitreid-connect/
- https://www.mediawiki.org/wiki/Extension:OpenID_Connect
- https://github.com/wikimedia/mediawiki-extensions-OpenIDConnect
- Dex - A Federated OpenID Connect ProviderIntegrate any identity provider into your application using OpenID Connect. Federate across upstream identity providers with ease. Dex supports a wide range of identity providers such as LDAP, SAML, and OAuth2 and implements OpenID Connect (OIDC), allowing your application to plug in any upstream identity provider, but implement only OIDC. Whether you’re looking to secure your internal applications, provide seamless Single Sign-On (SSO) across your organization, or create a secure public-facing platform, Dex can be tailored to meet your unique requirements. Avoid implementing registration and login forms when you don’t have to. Let users login with the identity provider of their (or your) choice and focus on your application logic instead of securing identity management.
WebID
2011
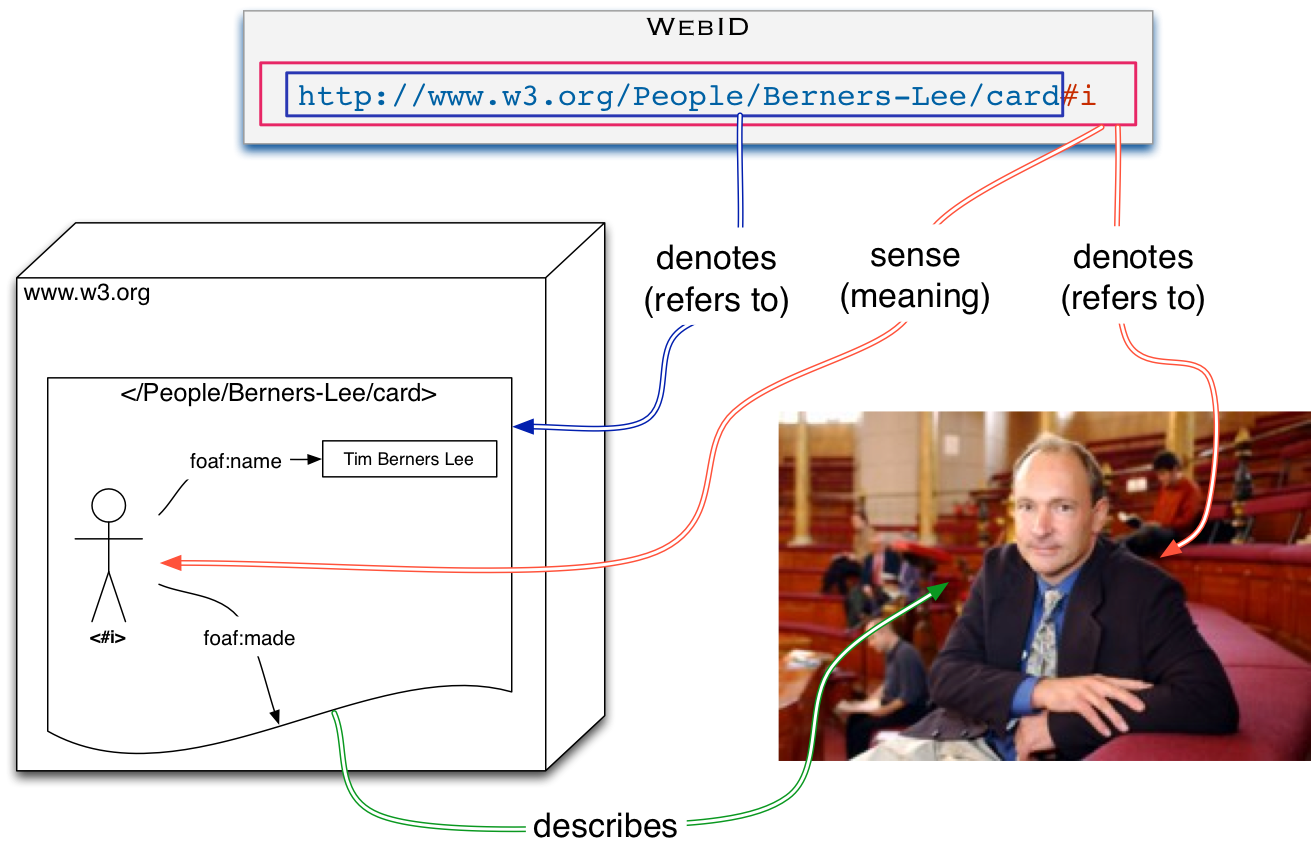{kind=link}
- https://en.wikipedia.org/wiki/FOAF_(ontology)#WebID_Protocol
- http://www.w3.org/wiki/WebID - was 'FOAF+SSL'
- http://www.w3.org/2005/Incubator/webid/wiki/User_Stories - active-ish
- http://buddypress.org/support/topic/webid-versus-openid-connect/
- http://semanticweb.com/time-for-another-look-at-webid_b21579
- http://bblfish.net/tmp/2010/08/05/webid-related.respec.html
- http://news.softpedia.com/news/W3C-Launches-WebID-Development-Group-for-Browser-Authentication-178496.shtml
- http://bblfish.net/tmp/2011/04/26/
- http://bblfish.net/blog/2011/05/25/
- http://yorkporc.wordpress.com/2012/10/03/myopenid-oauth-persona-webid-bridge/
- WebID-JSON-LD Specification - extends the WebID protocol to include JSON-LD formatted RDF responses, providing a structured, decentralized method for identity discovery via a JSON-based data format.
BrowserID / Persona
2011
- Introducing BrowserID: A better way to sign in - Jul 14, 2011
- MDN: Identity Provider Overview
- BrowserID - This is the production BrowserID specification, working live at https://login.persona.org.
- https://login.persona.org
- https://developer.mozilla.org/en/BrowserID/Quick_Setup
- Persona - repository contains the core Mozilla Persona services.
- EyeDee.Me - EyeDee.Me is an example Indentity Provider for the BrowserID protocol. This protocol is used by Mozilla Persona to authenticate users across the web. EyeDee.Me styles itself like an email provider, but does not actually handle any email. Rather, it exists solely as an example for how services, such as email providers, can provide first-class support for BrowserID.
- BigTent - A ProxyIdP service for bridging major IdPs who lack support for the BrowserID protocol.
- checkmyidp.org - A Mozilla Persona Identity Provider (IdP) Linter
- 123done - your tasks - simplified. test login.
- https://drupal.org/project/persona
- https://drupal.org/project/browserid_idp
- DrupalCon Prague 2013: Mozilla Persona: The Web's Decentralised Identity API - Jonathan Brown (Bluedroplet), Dan Callahan (Mozilla)
- Hypersona - Mozilla Persona's viability in Hyperboria
- http://upon2020.com/blog/2014/02/on-mozillas-persona-post-mortem/
- http://identity.mozilla.com/post/78873831485/transitioning-persona-to-community-ownership [31]
IndieAuth
2011
- IndieAuth is a way to use your own domain name to sign in to websites. It's like OpenID, but simpler! It works by linking your website to one or more authentication providers such as Twitter or Google, then entering your domain name in the login form on websites that support IndieAuth.
- http://indiewebcamp.com/IndieAuth - IndieAuth is an implementation of Web sign-in/RelMeAuth with a REST API on top.
- https://github.com/fmarier/indieauth-personaidp-spec
- http://aaronparecki.com/articles/2013/09/15/1/indieauth-now-supports-openid-delegation
url, not uri. costs a domain, digital divide..
SQRL
- GRC: SQRL - Secure (QR) Login. Proposing a comprehensive, easy-to-use, high security replacement for usernames, passwords, reminders, one-time-code authenticators and everything else.
WebAuth
- WebAuth - A Plugin Replacement for HTTPS CCA
WebAuthn
BitShares Login
- BitShares Login - has since pivoted? [36]
U2F
- Universal 2nd Factor - open ecosystem documents, an initiative started by Google. The intent is to enable Internet users to carry a non-phishable strong 2 factor device which the user can register at any supporting site to get strong authentication security. The goal is to get many internet services accepting these devices as an option for 2nd Factor, get the key client platforms (browsers, OSes) to have built in support for these open-protocol devices and a large number of vendors making protocol compliant devices.
gpgAuth
- gpgAuth is an authentication mechanism which uses Public/Private (cryptographic) keys (such as GnuPG, PGP) to authenticate users to a web-page or service. The process works by the two-way exchange of Encrypted/Signed tokens between a user and the service. gpgAuth is a generic authentication protocol that is not specific to any technology, platform or provider type. Being a versitile authentication mechansim, there are many hardware/software options available - in the projects section you will find information regarding various gpgAuth client and server implementations or tools.
Login with SSH
- Login with SSH - a simple experiment to authenticate web sessions with SSH. Doing so gives you a fully decentralized, passwordless authentication for free. A custom SSH server listens for connections. Instead of providing a shell or any other service, it only validates the public key you offer. Then, a callback is made to a web application with a payload containing the validated public key along with the login token used. In practise, you would have first hit a "login with SSH button" on the web app. It would have generated a session that resolves into a valid one with a callback handing the proper key / token combination.[37]
JSON Web Tokens
- https://en.wikipedia.org/wiki/JSON_Web_Token - JWT, is a JSON-based open standard (RFC 7519) for creating access tokens that assert some number of claims. For example, a server could generate a token that has the claim "logged in as admin" and provide that to a client. The client could then use that token to prove that it is logged in as admin. The tokens are signed by one party's private key (usually the server's), so that both parties (the other already being, by some suitable and trustworthy means, in possession of the corresponding public key) are able to verify that the token is legitimate. The tokens are designed to be compact, URL-safe and usable especially in web browser single sign-on (SSO) context. JWT claims can be typically used to pass identity of authenticated users between an identity provider and a service provider, or any other type of claims as required by business processes. JWT relies on other JSON-based standards: JWS (JSON Web Signature) RFC 7515 and JWE (JSON Web Encryption) RFC 7516.
SAML
- https://en.wikipedia.org/wiki/Security_Assertion_Markup_Language - AML, pronounced SAM-el) is an open standard for exchanging authentication and authorization data between parties, in particular, between an identity provider and a service provider. SAML is an XML-based markup language for security assertions (statements that service providers use to make access-control decisions). SAML is also: A set of XML-based protocol messages; A set of protocol message bindings; A set of profiles (utilizing all of the above)The single most important use case that SAML addresses is web browser single sign-on (SSO). Single sign-on is relatively easy to accomplish within a security domain (using cookies, for example) but extending SSO across security domains is more difficult and resulted in the proliferation of non-interoperable proprietary technologies. The SAML Web Browser SSO profile was specified and standardized to promote interoperability] (For comparison, the more recent OpenID Connect protocol is an alternative approach to web browser SSO.)
re:claimID
- https://gitlab.com/reclaimid
- https://github.com/reclaimID - The decentralized, self-sovereign identity system
- -1805.06253- reclaimID: Secure, Self-Sovereign Identities using Name Systems and Attribute-Based Encryption - "In this paper we present reclaimID: An architecture that allows users to reclaim their digital identities by securely sharing identity attributes without the need for a centralised service provider. We propose a design where user attributes are stored in and shared over a name system under user-owned namespaces. Attributes are encrypted using attribute-based encryption (ABE), allowing the user to selectively authorize and revoke access of requesting parties to subsets of his attributes. We present an implementation based on the decentralised GNU Name System (GNS) in combination with ciphertext-policy ABE using type-1 pairings. To show the practicality of our implementation, we carried out experimental evaluations of selected implementation aspects including attribute resolution performance. Finally, we show that our design can be used as a standard OpenID Connect Identity Provider allowing our implementation to be integrated into standard-compliant services."
- media.ccc.de - re:claimID - Self-sovereign, Decentralised Identity Management and Personal Data Sharing [YBTI/wefixthenet session - "In this talk, we present the current state of re:claimIDas well as a future roadmap."
Discovery
- The Discovery Protocol Stack, Redux - Nov 24th 2009
XRD / XRDS
XRD: Extensible Resource Descriptor XRDS: Extensible Resource Descriptor Sequence
The XML format used by XRDS was originally developed in 2004 by the OASIS XRI (extensible resource identifier) Technical Committee as the resolution format for XRIs. The acronym XRDS was coined during subsequent discussions between XRI TC members and OpenID developers at first Internet Identity Workshop held in Berkeley, CA in October 2005. The protocol for discovering an XRDS document from a URL was formalized as the Yadis specification published by Yadis.org in March 2006. Yadis became the service discovery format for OpenID 1.1.
A common discovery service for both URLs and XRIs proved so useful that in November 2007 the XRI Resolution 2.0 specification formally added the URL-based method of XRDS discovery (Section 6). This format and discovery protocol subsequently became part of OpenID Authentication 2.0. In early 2008, work on OAuth discovery by Eran Hammer-Lahav led to the development of XRDS Simple, a profile of XRDS that restricts it to the most basic elements and introduces some extensions to support OAuth discovery and other protocols that use specific HTTP methods. In late 2008, XRDS Simple has been cancelled and merged back into the main XRDS specification resulting in the upcoming XRD 1.0 format.
- Extensible Resource Descriptor (XRD) Version 1.0 - OASIS Standard, 1 November 2010. "This document defines XRD (Extensible Resource Descriptor), a simple generic format for describing resources. Resource descriptor documents provide machine-readable information about resources (resource metadata) for the purpose of promoting interoperability. They also assist in interacting with unknown resources that support known interfaces. For example, a web page about an upcoming meeting can provide in its descriptor document the location of the meeting organizer's free/busy information to potentially negotiate a different time. The descriptor for a social network profile page can identify the location of the user's address book as well as accounts on other sites. A web service implementing an API protocol can advertise which of the protocol's optional components are supported."
- https://wiki.oasis-open.org/xri/XrdOne/SpecHome - This is the home page for the XRD 1.0 specification. See SpecNaming for detailed filenames.
- XRD Alignment with Link Syntax | hueniverse - "a simple generic format for describing resources. Unlike past attempts, this time we got it right, and truly deliver on the promise of simple. In fact, the XRI TC spent the past year throwing features out if they were not supported by well-established use cases. Last month the specification reached the important milestone of a Committee Draft and was opened for public comments. While public review is open until January 6th (and we encourage feedback), we decide to publish a new working draft to address comments we already reach consensus on to help early adopters."
- https://en.wikipedia.org/wiki/Extensible_Resource_Identifier#Resolving_an_Extensible_Resource_Identifier - a scheme and resolution protocol for abstract identifiers compatible with Uniform Resource Identifiers and Internationalized Resource Identifiers, developed by the XRI Technical Committee at OASIS (closed in 2015). The goal of XRI was a standard syntax and discovery format for abstract, structured identifiers that are domain-, location-, application-, and transport-independent, so they can be shared across any number of domains, directories, and interaction protocols.The XRI 2.0 specifications were rejected by OASIS, a failure attributed to the intervention of the W3C Technical Architecture Group which recommended against using XRIs or taking the XRI specifications forward. The core of the dispute is whether the widely interoperable HTTP URIs are capable of fulfilling the role of abstract, structured identifiers, as the TAG believes, but whose limitations the XRI Technical Committee was formed specifically to address. The designers of XRI believed that, due to the growth of XML, web services, and other ways of adapting the Web to automated, machine-to-machine communications, it was increasingly important to be able to identify a resource independent of any specific physical network path, location, or protocol in order to: Create structured identifiers with self-describing "tags" that can be understood across domains. Maintain a persistent link to the resource regardless of whether its network location changes. Delegate identifier management not just in the authority segment (the first segment following the "xxx://" scheme name) but anywhere in the identifier path. Map identifiers used to identify a resource in one domain to other synonyms used to identify the same resource in the same domain, or in other domains.This work led, by early 2003, to the publication of a protocol based on HTTP(S) and simple XML documents called XRDS (Extensible Resource Descriptor Sequence).
.well-known
- RFC5785: Defining Well-Known Uniform Resource Identifiers (URIs) - defines a path prefix for "well-known locations", "/.well-known/", in selected Uniform Resource Identifier (URI) schemes.
- RFC 5785: Defining Well-Known URIs - April 6th 2010
older;
- http://tools.ietf.org/html/draft-hammer-discovery-06 - LRDD: Link-based Resource Descriptor Discovery
- http://tools.ietf.org/html/draft-hammer-hostmeta-17 - Web Host Metadata
newer;
- Simple Web Discovery (SWD) defines an HTTPS GET based mechanism to discover the location of a given type of service for a given principal starting only with a domain name.
Web Linking
- RFC5899: Web Linking - specifies relation types for Web links, and defines a registry for them. It also defines the use of such links in HTTP headers with the Link header field.
WebFinger
- WebFinger is a .well-known based protocol that aims to provide information about people by their E-mail addresses. It moves the old UNIX Finger protocol to the web by relying on HTTP only. It provides meta data about the user behind the E-mail address, for example public encryption keys and OpenIDs. The WebFinger protocol is used by the federated social networks StatusNet and Diaspora to discover users on federated nodes and pods as well as the remotestorage protocol used by e.g. ownCloud.
- WebFist uses DKIM-signed email to prove that you, the user, want to participate in WebFinger, regardless of what your provider says. By sending a single email you can delegate your WebFinger profile to your own website host or anything that can serve the service document over HTTP (e.g., Google Drive). This is ridiculously easy for users. You can even set up WebFist via a mailto link on a webpage. To accomplish decentralization, WebFist servers take delegation emails, encrypt them into blobs, and distribute the blobs safely across a pool of peer servers. These servers synchronize with a "fist bump", transferring just encrypted blobs without secret keys. This makes it near impossible to enumerate every email address in WebFist.
JSON Resource Descriptor
- JSON Resource Descriptor (JRD) is a simple JSON object that describes a "resource" on the Internet, where a "resource" is any entity on the Internet that is identified via a URI or IRI. For example, a person's account URI (e.g., acct:bob@example.com) is a resource. So are all web URIs (e.g., http://www.packetizer.com/). The JSON Resource Descriptor, originally introduced in RFC 6415 and based on the Extensible Resource Descriptor (XRD) format, was adopted for use in the WebFinger protocol, though its use is not restricted to WebFinger or RFC 6415.
- JRD, the Other Resource Descriptor - May 24th 2010
- RFC6415: Web Host Metadata
Also used in OpenID Connect.
Web Intents
- Web Intents is a framework for client-side service discovery and inter-application communication. Services register their intention to be able to handle an action on the user's behalf. Applications request to start an Action of a certain verb (share, edit, view, pick etc.) and the system will find the appropriate Services for the user to use based on the user's preference. Web Intents puts the user in control of service integrations and makes the developer's life simple.
UserAddress
- UserAddress is a search engine that can discover users as long as they are discoverable through one of the following languages: xrd (e.g. Webfinger including StatusNet, Google+, Friendica, Diaspora), rdf (e.g. Foaf), html (e.g. Tantek, Melvin), turtle (e.g. Facebook), Twitter-flavoured json (Twitter), Planned: xmpp-vcard (e.g. BuddyCloud)
Nodeinfo2
- https://git.feneas.org/jaywink/nodeinfo2 - NodeInfo2 is an effort to create a standardized way of exposing metadata about a server. This might be necessary to expose ownership and organization details, usage statistics and protocol capabilities.
Profile
vcard
hcard
- hCard is a microformat that allows a vCard to be embedded inside an HTML page. It makes use of CSS class names to identify each vCard property. Normal HTML markup and CSS styling can be used alongside the hCard class names without affecting the webpage's ability to be parsed by a hCard parser.
avatar
- http://pavatar.com/ - dead
attention
- http://www.apml.areyoupayingattention.com/
- http://www.bbc.co.uk/blogs/radiolabs/2008/05/were_playing_your_song_persona.shtml
Posting
Blogger API
- Google: Blogger API v3
MetaWeblog
2002
- RFC: MetaWeblog API - a programming interface that allows external programs to get and set the text and attributes of weblog posts. It builds on the popular XML-RPC communication protocol, with implementations available in many popular programming environments. The MetaWeblog API is designed to enhance the Blogger API, which was limited in that it could only get and set the text of weblog posts. By the time MWA was introduced, in spring 2002, many weblog tools had more data stored with each post, and without an API that understood the extra data, content creation and editing tools could not access the data. At the time of this writing, summer 2003, most popular weblog tools and editors support both the Blogger API and the MetaWeblog API.
- https://en.wikipedia.org/wiki/MetaWeblog - an application programming interface created by software developer Dave Winer that enables weblog entries to be written, edited, and deleted using web services. The API is implemented as an XML-RPC web service with three methods whose names describe their function: metaweblog.newPost(), metaweblog.getPost() and metaweblog.editPost(). These methods take arguments that specify the blog author's username and password along with information related to an individual weblog entry.
The impetus for the creation of the API in 2002 was perceived limitations of the Blogger API, which serves the same purpose. Another weblog publishing API, the Atom Publishing Protocol became an IETF Internet standard (RFC 5023) in October 2007. Subsequently, another weblog publishing API, Micropub, which was developed with modern technologies like OAuth, became a W3C Recommendation in May 2017. Many blog software applications and content management systems support the MetaWeblog API, as do numerous desktop clients.
AtomPub
- Atom Publishing Protocol - based on HTTP and is used for publications and posting on Web resources. The Atom Publishing Protocol (APP) together with the Atom Syndication Format (ASF) provides interaction with content, especially at blogs and RSS. Atom has become a popular element of Web 2.0-style solutions. APP/ASF represent a data model, which is simpler than WebDAV model, and consists of elements and selection of elements (entries), but doesn’t include location of selections (hierarchy of selection).
- The Atom Publishing Protocol - an application-level protocol for publishing and editing Web resources. The protocol is based on HTTP transfer of Atom-formatted representations. The Atom format is documented in the Atom Syndication Format.
- https://tools.ietf.org/html/rfc5023
- http://datatracker.ietf.org/wg/atompub/charter
- Blogger Developers Network - Blogger API Update
- XML.com: The Atom API
- AtomSub - Transporting Atom Notifications over the Jabber/XMPP Publish-Subscribe Extension to the Extensible Messaging and Presence Protocol (XMPP)]
MicroPub
- https://indieweb.org/Micropub - an open API standard (W3C Recommendation) that is used to create, update, and delete posts on one's own domain using third-party clients, and supersedes both MetaWeblog and AtomPub. Web apps and native apps (e.g. iPhone, Android) can use Micropub to post and edit articles, short notes, comments, likes, photos, events, or other kinds of posts to your own site.
- Micropub - The Micropub protocol is used to create, update and delete posts on one's own domain using third-party clients. Web apps and native apps (e.g., iPhone, Android) can use Micropub to post and edit articles, short notes, comments, likes, photos, events or other kinds of posts on your own website.
- https://github.com/w3c/Micropub - Micropub
- Micropub Rocks! - a validator to help you test your Micropub implementation. Several kinds of tests are available on the site.
Pub/sub
- https://en.wikipedia.org/wiki/Publish–subscribe_pattern - a messaging pattern where senders of messages, called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead categorize published messages into classes without knowledge of which subscribers, if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are. Publish–subscribe is a sibling of the message queue paradigm, and is typically one part of a larger message-oriented middleware system. Most messaging systems support both the pub/sub and message queue models in their API, e.g. Java Message Service (JMS). This pattern provides greater network scalability and a more dynamic network topology, with a resulting decreased flexibility to modify the publisher and the structure of the published data.
Jabber/XMPP PubSub
2002
- http://radar.oreilly.com/2008/07/oscon-day-1-beyond-rest-buildi.html
- http://www.isode.com/whitepapers/xmpp-pubsub.html
- http://blog.fanout.io/2013/10/09/publishing-json-over-xmpp/ [39]
WebSub
2008
- https://www.w3.org/TR/websub/
- https://github.com/w3c/websub - The WebSub specification is produced by the W3C Social Web Working Group.
- https://indieweb.org/WebSub - previously known as PubSubHubbub or PuSH, and briefly PubSub, is a notification-based protocol for web publishing and subscribing to streams and legacy feed files in real time. Currently there are no known indieweb sites that subscribe to anything via WebSub, but there are a few separate-UI indie-readers that use WebSub to subscribe to h-feed streams. WebSub is developed in the W3C Social Web Working Group.
older;
- PubSubHubbub (PuSH) - A simple, open, server-to-server webhook-based pubsub (publish/subscribe) protocol for any web accessible resources.
- Notes / PubSubHubbub - Oct 3rd 2010
trsst
2013
- Trsst: a secure and distributed blog platform for the open web
- Make a Twitter out of RSS - Dave Winer, March 28, 2013.
http-subscriptions
2013. Via WebHooks.
App.net
Feeds / Activity
- See Feeds / Activity
Linkbacks
Ping
1999
Trackback
2002
- Six Apart - Labs: Trackback - uses a REST model, where requests are made through standard HTTP calls. To send a TrackBack ping, the client makes a standard HTTP request to the server, and receives a response in a simple XML format (see below for more details). In the TrackBack system, the URL that receives TrackBack pings is the TrackBack Ping URL. A typical TrackBack Ping URL looks like http://www.example.com/trackback/5, where 5 is the TrackBack ID. Server implementations can use whatever format makes sense for the TrackBack Ping URL; client implementations should not depend on a particular format. To send a ping, the client sends an HTTP POST request to the TrackBack Ping URL. The client MUST send a Content-Type HTTP header, with the content type set to application/x-www-form-urlencoded. The client SHOULD include the character encoding of the content being sent (title, excerpt, and weblog name) in the charset attribute of the Content-Type header.
Semantic Trackback
2002
Semantic TrackbackTrackback (33) is a system whereby one blog entry can reference another, and automatically have this reference placed on both blog entries, thereby creating a binary link. This is useful to bloggers, so they can find out easily who is blogging about their content. The web does not have a mechanism itself to permit the creation of binary links, and regular hyperlinks on the web are unary in nature.The idea of a Semantic Trackback system is that instead of simply creating a binary link between two pages, as trackback currently enables, that link could carry knowledge and meaning with it. The meaning of a link at present, at least to a PageRank (7) system, is a vote for the other page, an assumption that publishing a link to somewhere not preferred by the posters would not happen. This behaviour has changed slightly in recent time, with the use of a rel=nofollow (30) to signify a link that should not be considered a positive vote of that page, mainly to curb the effect of "comment spam" on blogs. A Semantic Trackback system could apply more knowledge than a yea or nea about the linked artefact via an RDF graph to the link. For example, if somebody blogged about going to a Zoo, another blogger could create a Semantic Trackback link supported by an RDF graph that describes the fact that that person went with them, all using the same interaction as bloggers currently use to create ordinary trackbacks. This kind of acton-confirming information is useful to trust systems, as well as friend systems, since when the other user confirms the link, it asserts into the system that both parties agree they went to the Zoo on that day. Such confirmation brings the mundane into the Semantic Web trust layer.Semantic Trackback might also be used in a way similar to the "seeAlso" predicate is used in the RDF Syntax ontology (5) to create a link to more data about a particular resource.
Pingback
2002
- https://en.wikipedia.org/wiki/Pingback - an XML-RPC request (not to be confused with an ICMP ping) sent from Site A to Site B, when an author of the blog at Site A writes a post that links to Site B. The request includes the URI of the linking page. When Site B receives the notification signal, it automatically goes back to Site A checking for the existence of a live incoming link. If that link exists, the pingback is recorded successfully. This makes pingbacks less prone to spam than trackbacks. Pingback-enabled resources must either use an X-Pingback header or contain a <link> element to the XML-RPC script.
Semantic Pingback
- Semantic Pingback - The Semantic Pingback mechanism is an extension of the well-known Pingback method, a technological cornerstone of the blogosphere, thus supporting the interlinking within the Data Web.
- https://github.com/AKSW/SemanticPingback - This small vocabulary defines resources which are used in the context of Semantic Pingback. The Semantic Pingback mechanism is an extension of the well-known Pingback method, a technological cornerstone of the blogosphere, thus supporting the interlinking within the Data Web.] - This small vocabulary defines resources which are used in the context of Semantic Pingback. The Semantic Pingback mechanism is an extension of the well-known Pingback method, a technological cornerstone of the blogosphere, thus supporting the interlinking within the Data Web
Refback
2011
- https://en.wikipedia.org/wiki/Refback - simply the usage of the HTTP referrer header to discover incoming links. Whenever a browser traverses an incoming link from Site A (originator) to Site B (receptor) the browser will send a referrer value indicating the URL from where the user came. Site B might publish a link to Site A after visiting Site A and extracting relevant information from Site A such as the title, meta information, the link text, and so on. Refback only requires Site B to be Refback enabled in order to establish this communication. Refback requires Site A to physically link to Site B. Refback also requires browsers to traverse the links.
WebMention
2012
- http://webmention.org/ - A modern alternative to Pingback.
- http://webmention.io/ is an open-source project and hosted service for receiving webmentions and pingbacks on behalf of your indieweb site.
Comments
CommentAPI
Salmon
- Salmon Protocol is a message exchange protocol running over HTTP designed to decentralize commentary and annotations made against newsfeed articles such as blog posts. It allows a single discussion thread to be established between the article's origin and any feed reader or "aggregator" which is subscribing to the content. Put simply, that if an article appeared on 3 sites A (the source), B and C (the aggregates), that members of all 3 sites could see and contribute to a single thread of conversation regardless of site they were viewing from.
WebMention
- http://indiewebcamp.com/comment - are displayed in the context of an original post, and may be a mix of syndicated reply posts from other sites received via Webmention, as well as locally created comments.
- https://indieweb.org/Webmention - a web standard for mentions and conversations across the web, a powerful building block that is used for a growing federated network of comments, likes, reposts, and other rich interactions across the decentralized social web.
- https://indieweb.org/Salmention - a protocol extension to Webmention to propagate comments and other interactions upstream by sending a webmention from a response to the original post when the response itself receives a response (comment, like, etc.). The original post then checks the response to the original, parses the response to the response (e.g. comment on a comment) and then displays it as an additional response on the original post.
Isso
- Isso - a commenting server similar to Disqus. Comments written in Markdown Users can edit or delete own comments (within 15 minutes by default). Comments in moderation queue are not publicly visible before activation. SQLite backend Because comments are not Big Data. Disqus & WordPress Import. You can migrate your Disqus/WordPress comments without any hassle. Configurable JS client Embed a single JS file, 65kB (20kB gzipped) and you are done. Supports Firefox, Safari, Chrome and IE10. [45]
Interaction
XML-RPC
1998
Jabber/XMPP Data Forms
2001
- XEP-0004: Data Forms - an XMPP protocol extension for data forms that can be used in workflows such as service configuration as well as for application-specific data description and reporting. The protocol includes lightweight semantics for forms processing (such as request, response, submit, and cancel), defines several common field types (boolean, list options with single or multiple choice, text with single line or multiple lines, single or multiple JabberIDs, hidden fields, etc.), provides extensibility for future data types, and can be embedded in a wide range of applications. The protocol is not intended to provide complete forms-processing functionality as is provided in the W3C XForms technology, but instead provides a basic subset of such functionality for use by XMPP entities.
- https://xmpp.org/extensions/xep-0141.html - This specification defines a backwards-compatible extension to the XMPP Data Forms protocol that enables an application to specify form layouts, including the layout of form fields, sections within pages, and subsections within sections.
XForms
2003
- XForms 1.1 - W3C Recommendation 20 October 2009
- XForms 2.0 - W3C Working Draft 7 August 2012
- https://en.wikipedia.org/wiki/XForms - an XML format used for collecting inputs from web forms. XForms was designed to be the next generation of HTML / XHTML forms, but is generic enough that it can also be used in a standalone manner or with presentation languages other than XHTML to describe a user interface and a set of common data manipulation tasks.XForms 1.0 (Third Edition) was published on 29 October 2007. The original XForms specification became an official W3C Recommendation on 14 October 2003, while XForms 1.1, which introduced a number of improvements, reached the same status on 20 October 2009.
- https://github.com/dimagi/Vellum - a JavaRosa XForm designer used in CommCare HQ.
CMIS
See Organising#CMIS
2010
- https://en.wikipedia.org/wiki/Content_Management_Interoperability_Services - an open standard that allows different content management systems to inter-operate over the Internet. Specifically, CMIS defines an abstraction layer for controlling diverse document management systems and repositories using web protocols.
Atom Publishing Protocol (APP)
OExchange
- OExchange is an open protocol for sharing any URL with any service on the web.
Web Intents
- Web Intents is a framework for client-side service discovery and inter-application communication. Services register their intention to be able to handle an action on the user's behalf. Applications request to start an Action of a certain verb (share, edit, view, pick etc.) and the system will find the appropriate Services for the user to use based on the user's preference.
Ballista
Graph
FOAF
2000
FOAF (from "friend of a friend") is an RDF based schema to describe persons and their social network in a semantic way. FOAF could get used within many wikis for annotating user pages, or describing articles about people.
See Open web#WebID
XFN
2006
- XFN - XHTML Friends Networka simple way to represent human relationships using hyperlinks. In recent years, blogs and blogrolls have become the fastest growing area of the Web. XFN enables web authors to indicate their relationship(s) to the people in their blogrolls simply by adding a 'rel' attribute to their <a href> tags, [47]
- http://microformats.org/wiki/xfn-hcard-supporting-friends-lists
- http://microformats.org/wiki/xfn-implementations
Portable Contacts
2008
The protocol is a combination of OAuth, XRDS-Simple and a wire-format based on vCard harmonized with schema from OpenSocial.
Other
Storage
remoteStorage
- remoteStorage - the first (and currently only) open standard to enable truly unhosted web apps. That means users are in full control of their precious data and where it is stored, while app developers are freed of the burden of hosting, maintaining and protecting a central database.
Networks
See also Comms, Network#Projects
theory and practice
- https://docs.google.com/spreadsheet/ccc?key=0AtXMsLaocacrdDAwTzdPeGdPNlhZSHFMelg0MnQ2N2c#gid=0
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/Platforms
GNUnet
2001
- GNUnet is a framework for secure peer-to-peer networking that does not use any centralized or otherwise trusted services. A first service implemented on top of the networking layer allows anonymous censorship-resistant file-sharing. Anonymity is provided by making messages originating from a peer indistinguishable from messages that the peer is routing. All peers act as routers and use link-encrypted connections with stable bandwidth utilization to communicate with each other. GNUnet uses a simple, excess-based economic model to allocate resources. Peers in GNUnet monitor each others behavior with respect to resource usage; peers that contribute to the network are rewarded with better service. GNUnet is part of the GNU project. GNUnet can be downloaded from GNU and the GNU mirrors.
Kune
2007
xOperator
2007
- xOperator - A semantic agent for xmpp / jabber network which finds and shares content about resources (using RDF/SPARQL) for you and your jabber friends.
Sneer
2008
- Sneer is a free and open source sovereign computing platform. It runs on your Windows, Mac or Linux machine (like Skype or Firefox) using the Java VM. It enables you to create your personal cluster by sharing hardware resources (CPU, disk space, network bandwidth) with your friends, host your own social network, information and media, create sovereign applications and share them with others, download and run sovereign applications created by others.
Semantic Microblogging
2008
OpenLink Data Spaces
2009
Diaspora
2010
GNU Social
2010. uses older OStatus
- http://programmingisterrible.com/post/39438834308/distributed-social-network
- http://we-need-a-free-and-open-social-network.wikispaces.com/Federated+Social+Network+Applications
- https://git.gnu.io/h2p/Qvitter - UI for GNU social
- https://git.gnu.io/gnu/gnu-social/issues/256 - Support ActivityPub
- https://git.gnu.io/dansup/ActivityPub - ActivityPub Plugin for GNU Social
Foafpress
2010
- Foafpress - An open-source PHP web application and presentation engine that publishes profiles and web pages based on RDF data stored in files. It allows you to aggregate and publish data from multiple web sources via Linked Data.
Jappix
2010
- https://jappix.com/ - xmpp based
buddycloud
2010
Mobile Social Semantic Web
2010
Friendica
2011
- friendica – A Decentralized Social Network
DSSN
2012
Nightweb
2012
- Nightweb is an app for Android devices and PCs that connects you to an anonymous, peer-to-peer social network. It is written in Clojure and uses I2P and BitTorrent on the backend.
Vole
2013
- Vole is a web-based social network that you use in your browser, without a central server. It's built on the power of Bittorrent, Go and Ember.js.
SOCML
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/SOCML_proposal
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/SOCML_Standard
- http://www.w3.org/2005/Incubator/federatedsocialweb/wiki/SOCML_Technical
Sockethub
- Sockethub is a polyglot (speaking many different protocols and APIs) messaging service for social and other interactive messaging applications. It assists web app developers by providing server-independent, server-side functionality - which gives the application greater autonomy. It can be used as a tool for many different types of applications, large and small.
Di.me
IRC Paradigm
2013
Aether
2013
- Aether - a peer-to-peer app, and it has no servers. A result of this is that source IP of any specific public post cannot (easily) be determined. Most people use pseudonyms, though you can use your real name, or company. Aether is private by default, so that you can choose to be fully private, or fully public yourself. Aether keeps a 6 months of content by default. It's gone after. If something is worth keeping, someone will save it within six months — but not from beyond that. If you screw up, argue for the wrong opinion, and then think otherwise, that's okay. No one is going to come after you — it gives you the freedom to be wrong, and move on. Actions of moderators are visible to users. No content can just 'disappear', if something gets deleted, you'll know who did it, why they did it, and if you want, how to get it back. Moderation is important for healthy communities, and Aether adds onto it some checks-and-balances. Everyone watches the watchmen. Communities can elect and impeach their own mods by voting. If a mod behaves inappropriately, users can disable that mod locally as well. [49]
Syme
2013
Twister
2013
- https://news.ycombinator.com/item?id=6990354
- http://www.wired.com/wiredenterprise/2014/01/twister/ [51]
Snake.il
Charme
- Charme - A decentralized social network with end-to-end encryption for messaging, private posts and private profile data. Posts can contain semantic information, so it is possible to search for all friends driving from A to B for example. This is a preview version. It is not secure yet!!! So do not wonder if you find some crypto mistakes!
Movim
Secure Scuttlebutt
- Scuttlebutt - a decent(ralised) secure gossip platform, peer-to-peer replicatable data structure
- https://github.com/dominictarr/scuttlebutt - peer-to-peer replicatable data structure
- https://github.com/ssbc
- https://github.com/ssbc/ssb-server - gossip and replication server for Secure Scuttlebutt
- In The Mesh: Scuttlebutt, A Decentralized Alternative To Facebook - [54]
- https://github.com/ssbc/patchwork - A decentralized messaging and sharing app built on top of Secure Scuttlebutt (SSB).
- Manyverse - A social network off the grid
- Planetary - mainstream client for a truly distributed social network.
Humhub
Mastodon
- https://joinmastodon.org/ [55]
- https://github.com/tootsuite/mastodon - A GNU Social-compatible microblogging server
- https://github.com/tootsuite/mastodon/releases/tag/v3.0.0 - Remove OStatus support. Please use ActivityPub instead. [56]
- YouTube: What is the Mastodon Social Network?
- Mastofeed - embeddable Mastodon feeds for blogs etc.
- TheDesk - Mastodon client for PC(Windows/Linux/macOS). Boost your Mastodon life, and also Misskey experience.
- Whalebird - a Mastodon and Pleroma client for desktop application
- https://github.com/enkiv2/fern - a curses-based mastodon client modeled off usenet news readers & pine, with an emphasis on getting to 'timeline zero'
Hubzilla
- Hubzilla Development - hubzilla@project.hubzilla.org - a powerful platform for creating interconnected websites featuring a decentralized identity, communications, and permissions framework built using common webserver technology.
Pleroma
- Pleroma - a federated social networking platform, compatible with GNU social and other OStatus implementations. It is free software licensed under the AGPLv3. It actually consists of two components: a backend, named simply Pleroma, and a user-facing frontend, named Pleroma-FE.
write.as / Write Freely
- Write Freely - free and open source software for starting a minimalist, federated blog — or an entire community. [57]
- Write.as - Minimalist, privacy-focused,writing and publishing platform.
- Write.as Guides - a lightweight publishing platform made for sharing your thoughts quickly. Publish text in a variety of shareable formats, from individual articles to blogs.
- https://github.com/writeas/write-as.vim - A simple VIM plugin that allows one to upload blogposts to write.as directly from the buffer.
- Read.as - Free and open source long-form reader.
honk
Farcaster
- Farcaster - a sufficiently decentralized social network. It is an open protocol that can support many clients, just like email.Users will always have the freedom to move their social identity between applications, and developers will always have the freedom to build applications with new features on the network.
- https://github.com/farcasterxyz/protocol - Specification of the Farcaster Protocol
Nostr
- Nostr - A decentralized social network with a chance of workingLearn about Nostr: A simple, open protocol that enables a truly censorship-resistant and global social network.
- https://github.com/nostr-protocol/nostr - a truly censorship-resistant alternative to Twitter that has a chance of working
- https://github.com/aljazceru/awesome-nostr - A curated list of nostr projects and resources
- https://github.com/tubomius/nostr-irc - Acts as an IRC server and a nostr client. Connect with your IRC client using your nostr private key as the password.
to sort
oEmbed
Hyperlocal
other
Fraidycat
- Fraidycat - a desktop app or browser extension for Firefox or Chrome. I use it to follow people (hundreds) on whatever platform they choose - Twitter, a blog, YouTube, even on a public TiddlyWiki.
OPDS
- https://en.wikipedia.org/wiki/Open_Publication_Distribution_System - catalog format is a syndication format for electronic publications based on Atom and HTTP. OPDS catalogs enable the aggregation, distribution, discovery, and acquisition of electronic publications. OPDS catalogs use existing or emergent open standards and conventions, with a priority on simplicity. The Open Publication Distribution System specification is prepared by an informal grouping of partners, combining Internet Archive, O'Reilly Media, Feedbooks, OLPC, and others.
- Open Publication Distribution System Validator - Unofficial Validator
Bridgy Fed
- Bridgy Fed - connects web sites, the fediverse, and Bluesky. You can use it to make your profile on one visible in another, follow people, see their posts, and reply and like and repost them. Interactions work in both directions as much as possible.
Pipedream
older ideas/ramblings
- http://web.archive.org/web/20110120002447/
- http://www.typewith.me/the-web-we-need - via anon activism
Social news idea
While I'm here (sending feedback for the new digg), my wishlist would be for;
- Reddit style voting meets Slashdot comment categories, with social bookmark tagging for both users and groups/communities. *
Between upvoting and commenting, there are other types of actions that can be performed on items, like flagging as a favourite.
To add a better social bookmarking management system (better than Reddit search!), if a user could either;
- Click to Digg - (Click to thumbs-down/whatever is optional for communities, or like Hacker News) - Click to Favourite to own bookmark list -- And Tag, like del.icio.us, pinboard.in - Also, click to "Notice", as in not like the user "Diggs" or "Likes" the content of the article, and not that they want to bother saving it to Favourites, but a touch in the sence of a the *nix command, or a 'poke' to the issue embodies in the linked to page.
So, on the page, in ASCII;
This is the title of the link! 324 diggs/94 undiggs (small url) 863 noticed [++] [*] [~] [Tag:] [img thumb/whatever]
This is the title of another link! 243 diggs/213 undiggs (small url) 546 noticed [++] [*] [~] [Tag:] [img thumb/whatever]
(the buttons representing 'digg', 'favourite/save', 'notice' and 'tag:'
the tag textarea expands on clickingm like the stackexchange search box, and does auto-complete for a users tags, with suggestions from the global tags, like del.icio.us. personal taxonomy can be cached locally for users.)
ALSO - reposts in different communities can tie back to a global site dashboard listing related taxonomies, from groups and users who favourite the link publically
So
- Bottom up social tagging link topic clustering
- Some communities have taxonomies moderated
- Moderated taxonomies could be linked with Linked Data, DPpedia, etc.
- So some serious bits of the site, some open and silly bits
- Bits and bobs displayed in a timeline format (D3.js?), arrows between concepts in a postcyberpunk style semantic news and search display
- Paid access for high-volume API calls
tag/category/channel ?
[social] bookmarks as service
Group types
from old wiki
Groups for collaboration on and sharing of conversation, news, code, media, services, etc.
- Active = Groups as in membership.
- Who can 'join'?
- Open = Cost of entry is participation.
- Closed = Some form of new-member rules.
- What output can people see?
- Public = Open process, easily forkable.
- Private = Group or subgroup curates output, hidden process. Trust?
- Who can 'join'?
- Passive = Groups as in topics of interest.
- Web of semantically related topics and ideas.
- Mining and 'routing' of relevant related content
Individual hubs could federate the service they wished (widgets, social aggregation, files, etc) in a manner that could be open or hidden. Tunnelled inter-darknet connections between anonymised users and services.
Process consensus-holders
Philosophy
- interoperable oss platform(s)
- activity stream, accessible for aggregation
- easy filterable by others
- from easy oembed style referencing using entry points with either html5 microformats or semantic apis
- following/friend activity aggregation.
- federated commenting
- provides with one public (https) and one private (hidden service)
- categories and tags the same
- category tags out-of-bound but in-band referable
- linked to evolving social fuzzy web ontology? npl for suggestions
- other services use same ontology for wikis and social bookmarking
- linked to evolving social fuzzy web ontology? npl for suggestions
- category tags out-of-bound but in-band referable
- easy link friends with post categories and