Semantic
{{menu}]
General
See also Open web#Semantic
- Semantic Web - a “Web of data,” the sort of data you find in databases. The ultimate goal of the Web of data is to enable computers to do more useful work and to develop systems that can support trusted interactions over the network. The term “Semantic Web” refers to W3C’s vision of the Web of linked data. Semantic Web technologies enable people to create data stores on the Web, build vocabularies, and write rules for handling data. Linked data are empowered by technologies such as RDF, SPARQL, OWL, and SKOS.
- Use URIs to denote things.
- Use HTTP URIs so that these things can be referred to and looked up ("dereferenced") by people and user agents.
- Provide useful information about the thing when its URI is dereferenced, leveraging standards such as RDF, SPARQL.
- Include links to other related things (using their URIs) when publishing data on the Web.
or
- All kinds of conceptual things, they have names now that start with HTTP.
- I get important information back. I will get back some data in a standard format which is kind of useful data that somebody might like to know about that thing, about that event.
- I get back that information it's not just got somebody's height and weight and when they were born, it's got relationships. And when it has relationships, whenever it expresses a relationship then the other thing that it's related to is given one of those names that starts with HTTP.
On the Semantic Web, vocabularies define the concepts and relationships (also referred to as “terms”) used to describe and represent an area of concern. Vocabularies are used to classify the terms that can be used in a particular application, characterize possible relationships, and define possible constraints on using those terms. In practice, vocabularies can be very complex (with several thousands of terms) or very simple (describing one or two concepts only).
There is no clear division between what is referred to as “vocabularies” and “ontologies”. The trend is to use the word “ontology” for more complex, and possibly quite formal collection of terms, whereas “vocabulary” is used when such strict formalism is not necessarily used or only in a very loose sense. Vocabularies are the basic building blocks for inference techniques on the Semantic Web.
- Agile Knowledge Engineering and Semantic Web (AKSW) is hosted by the Chair of Business Information Systems (BIS) of the Institute of Computer Science (IfI) / University of Leipzig as well as the Institute for Applied Informatics (InfAI). Goals: Development of methods, tools and applications for adaptive Knowledge Engineering in the context of the Semantic Web. Research of underlying Semantic Web technologies and development of fundamental Semantic Web tools and applications. Maturation of strategies for fruitfully combining the Social Web paradigms with semantic knowledge representation techniques.
- Sindice - Data Web Services. Millions of websites mark up their content using RDF, Microformats, Microdata, Schema.org, RDFa, Opengraph and more. Sindice helps you find, understand and integrate with their content.
- http://nets.ii.uam.es/~neptuno/publications/neptuno-esws04.pdf
- http://www.public.asu.edu/~hdavulcu/VLDB-WS03.pdf
- http://eb.ie.nthu.edu.tw/File/Faculty/Journal/J-08-A%20fuzzy%20ontological%20knowledge%20document%20clustering%20methodology.pdf
- http://dl.acm.org/citation.cfm?id=500767
- http://www.inf.unibz.it/dis/research/seminar_slides/hayes.pdf
- http://eprints.qut.edu.au/30315/1/Cher_Lau_Thesis.pdf
- http://www.is.informatik.uni-kiel.de/~thalheim/vorlesungen/Wirtschaftsinformatik/KnowledgeGridEJC10.pdf
- http://www.ontopia.net/topicmaps/materials/identitycrisis.html
- http://www.ltg.ed.ac.uk/~ht/eSI_URIs.html
- http://www.w3.org/2000/10/swap/ - Semantic Web Application Platform
- http://www.w3.org/2000/10/swap/doc/cwm.html
Linked Open Data
- W3C: Linking Open Data - The Open Data Movement aims at making data freely available to everyone. There are already various interesting open data sets available on the Web. Examples include Wikipedia, Wikibooks, Geonames, MusicBrainz, WordNet, the DBLP bibliography and many more which are published under Creative Commons or Talis licenses. The goal of the W3C SWEO Linking Open Data community project is to extend the Web with a data commons by publishing various open data sets as RDF on the Web and by setting RDF links between data items from different data sources. RDF links enable you to navigate from a data item within one data source to related data items within other sources using a Semantic Web browser. RDF links can also be followed by the crawlers of Semantic Web search engines, which may provide sophisticated search and query capabilities over crawled data. As query results are structured data and not just links to HTML pages, they can be used within other applications.
- Linked Data is about using the Web to connect related data that wasn't previously linked, or using the Web to lower the barriers to linking data currently linked using other methods. More specifically, Wikipedia defines Linked Data as "a term used to describe a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF." This site exists to provide a home for, or pointers to, resources from across the Linked Data community.
- datavisualization.ch: Introduction to Linked Open Data for Visualization Creators
- How to Publish Linked Data on the Web
- http://www.slideshare.net/DLFCLIR/intro-to-lod
- Learning Linked Data
- Learn Linked Data - Helping you get to grips with RDF, SPARQL & linked data.
- http://linkeddatabook.com/
- LOD cloud diagram shows datasets that have been published in Linked Data format, by contributors to the Linking Open Data community project and other individuals and organisations. It is based on metadata collected and curated by contributors to the Data Hub. Clicking the image will take you to an image map, where each dataset is a hyperlink to its homepage.
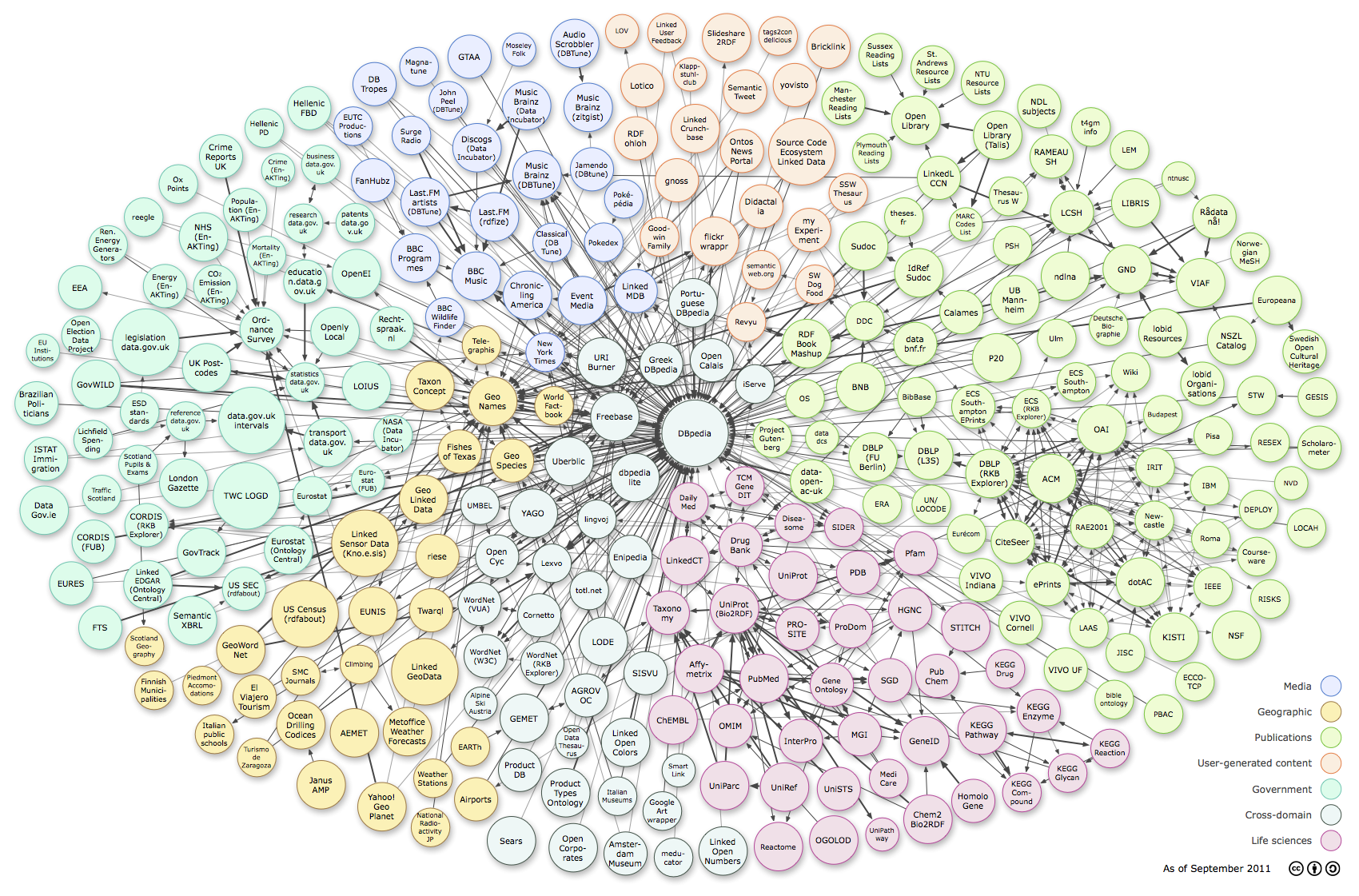{kind=link}
- LodLive project provides a demonstration of the use of Linked Data standards (RDF, SPARQL) to browse RDF resources. The application aims to spread linked data principles using a simple and friendly interface with reusable techniques.
- http://rww.io/ - webid
RFD
- http://en.wikipedia.org/wiki/Resource_Description_Framework
- W3C: RDF 1.1 Concepts and Abstract Syntax
RDF is a general method to decompose any type of knowledge into small pieces, with some rules about the semantics, or meaning, of those pieces. The point is to have a method so simple that it can express any fact, and yet so structured that computer applications can do useful things with it.
The basic unit of RDF is a statement called a triple. One can think of a triple as a type of sentence that states a single "fact" about a resource. RDF allows you to define statements about things (or resources), in the form of subject-predicate-object expressions (known as RDF-triples due to the 3 constituent parts).
- http://www.w3.org/TR/rdf-schema/ - RDF Vocabulary Description Language 1.0: RDF Schema
- http://www.w3.org/TR/rdf-mt/ - semantics
- Different RDF Formats - March 11 2013
The different forms for representing the RDF data are:
- RDF/XML
- Notation-3 (N3)
- Turtle - a simplified, RDF-only subset of N3.
- N-Triple
- RDFa
- TRiX
- TRiG
- JSON-LD
RDF/XML
Here's some RDF XML:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ns="http://www.example.org/#">
<ns:Person rdf:about="http://www.example.org/#john"> <ns:hasMother rdf:resource="http://www.example.org/#susan" /> <ns:hasFather> <rdf:Description rdf:about="http://www.example.org/#richard"> <ns:hasBrother rdf:resource="http://www.example.org/#luke" /> </rdf:Description> </ns:hasFather> </ns:Person> </rdf:RDF>
- HTTP Vocabulary in RDF 1.0
- TriG - RDF Dataset Language. A concrete syntax for RDF as defined in the RDF Concepts and Abstract Syntax ([rdf11-concepts]). TriG is an extension of Turtle ([turtle]), extended to support representing a complete RDF Dataset.
N3
Here's some N3 RDF:
@prefix : <http://www.example.org/> . :john a :Person . :john :hasMother :susan . :john :hasFather :richard . :richard :hasBrother :luke .
Turtle
N-Triple
RDFa
2004. RDFa 1.1 reached recommendation status in June 2012.
- RDFa is an extension to HTML5 that helps you markup things like People, Places, Events, Recipes and Reviews. Search Engines and Web Services use this markup to generate better search listings and give you better visibility on the Web, so that people can find your website more easily.
- HTML+RDFa 1.1 - Support for RDFa in HTML4 and HTML5 [1]
JSON-LD
- http://en.wikipedia.org/wiki/JSON-LD - RDF-like
JSON-LD was created by people that have been directly involved in the Linked Data, lowercase semantic web, uppercase Semantic Web, Microformats, Microdata, and RDFa work. It has proven to be useful to them. There are a number of very large technology companies that have adopted JSON-LD, further underscoring its utility.
Other
News
Libs
Vocabularies
- http://www.w3.org/standards/semanticweb/ontology
- http://semanticweb.org/wiki/Ontology
- https://en.wikipedia.org/wiki/Ontology_(information_science)#Examples_of_published_ontologies
- http://www.service-finder.eu/ontologies/ServiceOntology
Dublin Code
SKOS
- https://en.wikipedia.org/wiki/Simple_Knowledge_Organization_System
- http://lov.okfn.org/dataset/lov/details/vocabulary_skos.htmlhttps://en.wikipedia.org/wiki/Content_Management_Interoperability_Services
DOAP
- https://en.wikipedia.org/wiki/DOAP - product
SIOC
- http://rdfs.org/ - SIOC, ResumeRDF, SCOT
- SIOC initiative (Semantically-Interlinked Online Communities) aims to enable the integration of online community information. SIOC provides a Semantic Web ontology for representing rich data from the Social Web in RDF. It has recently achieved significant adoption through its usage in a variety of commercial and open-source software applications, and is commonly used in conjunction with the FOAF vocabulary for expressing personal profile and social networking information. By becoming a standard way for expressing user-generated content from such sites, SIOC enables new kinds of usage scenarios for online community site data, and allows innovative semantic applications to be built on top of the existing Social Web. The SIOC ontology was recently published as a W3C Member Submission, which was submitted by 16 organisations.
ResumeRDF
SCOT
- SCOT is an acronym for Social Semantic Cloud of Tags. The name was chosen to emphasise the goal of providing a consistent framework for expressing social tagging at a semantic level in machine-understandable way. The SCOT ontology provides a model for expressing the main concepts and properties required to describe information for tagging activities (e.g., users, tags, resources, etc.) on the Semantic Web. This document contains a detailed description of the SCOT Ontology.
Data Cube
- RDF Data Cube Vocabulary - There are many situations where it would be useful to be able to publish multi-dimensional data, such as statistics, on the web in such a way that it can be linked to related data sets and concepts. The Data Cube vocabulary provides a means to do this using the W3C RDF (Resource Description Framework) standard. The model underpinning the Data Cube vocabulary is compatible with the cube model that underlies SDMX (Statistical Data and Metadata eXchange), an ISO standard for exchanging and sharing statistical data and metadata among organizations. The Data Cube vocabulary is a core foundation which supports extension vocabularies to enable publication of other aspects of statistical data flows or other multi-dimensional data sets.
Other
- http://iswc2011.semanticweb.org/fileadmin/iswc/Papers/PostersDemos/swc/swc2011_submission_1.pdf
- http://dl.acm.org/citation.cfm?id=2396761.2398467
- http://vocab.org/relationship/.html
- http://motools.sourceforge.net/event/event.html#
- http://smiy.sourceforge.net/ao/spec/associationontology.html#
- http://smiy.sourceforge.net/rec/spec/recommendationontology.html#
- http://vocab.deri.ie/ppo
Tools
- W3C: RDFImportersAndAdapters
- W3C: ConverterToRdf converts application data from an application-specific format into RDF for use with RDF tools and integration with other data. Converters may be part of a one-time migration effort, or part of a running system which provides a semantic web view of a given application.
- Redland is a set of free software C libraries that provide support for the Resource Description Framework (RDF).
- Raptor is a free software / Open Source C library that provides a set of parsers and serializers that generate Resource Description Framework (RDF) triples by parsing syntaxes or serialize the triples into a syntax. The supported parsing syntaxes are RDF/XML, N-Quads, N-Triples, TRiG, Turtle, RDFa 1.0 and 1.1, RSS tag soup including all versions of RSS, Atom 1.0 and 0.3, GRDDL and microformats for HTML, XHTML and XML. The serializing syntaxes are RDF/XML (regular, and abbreviated), Atom 1.0, GraphViz, JSON, N-Quads, N-Triples, RSS 1.0 and XMP.
- rdfstore-js is a pure Javascript implementation of a RDF graph store with support for the SPARQL query and data manipulation language. node.js
- prefix.cc - namespace lookup for RDF developers
other
- http://www.w3.org/TR/microdata-rdf/
- http://www.thedigitalshift.com/2012/02/roy-tennant-digital-libraries/why-microdata-not-rdf-will-power-the-semantic-web/
- http://manu.sporny.org/2013/microdata-downward-spiral/
- [http://people.csail.mit.edu/emax/papers/atomate-www2010-camera.pdf Atomate It! End-user Context-Sensitive Automation using
Heterogeneous Information Sources on the Web
OWL
- http://www.michael-beisswenger.de/pub/model-wn-owl.pdf
- http://www.icsi.berkeley.edu/pubs/ai/DeLuca_LoennekerRodman_HMDXML.pdf
SPARQL
- http://dbpedia.org/sparql
- http://data.gov.uk/sparql
- http://www.cambridgesemantics.com/semantic-university/sparql-by-example#%281%29
LOV
GRDDL
- GRDDL is a mechanism for Gleaning Resource Descriptions from Dialects of Languages. It is a technique for obtaining RDF data from XML documents and in particular XHTML pages. Authors may explicitly associate documents with transformation algorithms, typically represented in XSLT, using a link element in the head of the document. Alternatively, the information needed to obtain the transformation may be held in an associated metadata profile document or namespace document.
- http://www.slideshare.net/chimezie/grddl-the-why-what-how-and-where
- http://microformats.org/wiki/grddl
- http://www.w3.org/2003/g/data-view
VOAF
Web Observatory
Python
JavaScript
- Sgvizler is a javascript which renders the result of SPARQL SELECT queries into charts or html elements. It is cool stuff (ivan_herman, timbl).
REST
See WebDev#API
- http://www.w3.org/TR/ldp/
- http://www.w3.org/2012/ldp/
- http://www.w3.org/2012/ldp/charter.html - Linked Data Platform (LDP) Working Group is to produce a W3C Recommendation for HTTP-based (RESTful) application integration patterns using read/write Linked Data. This work will benefit both small-scale in-browser applications (WebApps) and large-scale Enterprise Application Integration (EAI) efforts. It will complement SPARQL and will be compatible with standards for publishing Linked Data, bringing the data integration features of RDF to RESTful, data-oriented software development.
- http://lists.w3.org/Archives/Public/public-ldp-wg
- http://www.w3.org/Submission/ldbp/
Validation
Search
Other
See also MediaWiki#Semantic
- http://semanticweb.com/ - business news
- Virtuoso is an innovative enterprise grade multi-model data server for agile enterprises & individuals. It delivers an unrivaled platform agnostic solution for data management, access, and integration.
- URIBurner - A data virtualization service that transforms data hosted in a variety of data spaces and formats into standards compliant Linked Data Objects for uniform access, integration and management. The underlying technology is Virtuoso's in-built Linked Data Middleware (aka Sponger) that uses URLs as data source names for its powerful data ingestion and transformation services that result in highly navigable Linked Data Object graphs. Post transformation, each Data Object is endowed with a dereferenceable identifier (Name) that resolves to its actual representation via its URL (Address). The Sponger then re-presents Data Object descriptions via HTML documents (the default behavior) or in a variety of raw data graph forms that include: CSV, N-Triples, Turtle, N3, RDF/XML, JSON, CXML, OData (Atom and JSON) etc.
- Disco - Hyperdata Browser is a simple browser for navigating the Semantic Web as an unbound set of data sources. The browser renders all information, that it can find on the Semantic Web about a specific resource, as an HTML page. This resource description contains hyperlinks that allow you to navigate between resources. While you move from resource to resource, the browser dynamically retrieves information by dereferencing HTTP URIs and by following rdfs:seeAlso links.
- http://linkeddata.uriburner.com/about/html/http://linkeddata.uriburner.com/about/id/entity/http/www4.wiwiss.fu-berlin.de/rdf_browser/%01dfdd7716dd407d1986431f6511842236